Signalling and Synchronisation Issues
To signal data committed by the sender DSI uses packets that are enqueued in a ringbuffer at the control region. The control region is a shared DROPS memory region which is established at socket setup. The sender asks for a free packet, fills in its data and commits the packet. The receiver gets the packet from the control region, reads the data out of the packet and acknowledges the packet. A packet is called allocated after the sender requested it, it is called filled after the sender commited it. Otherwise a packet is considered as free.Synchronisation happens when getting a packet, commiting it or acknowledging a packet. It can be done asynchronously or synchronously. The send- and receive-components are not related in their synchronouity, one can work synchronous, the other one can work asynchronous. It can even be different for each packet.
In synchronous mode, the receiver is delayed on getting a packet until a packet is commited by the sender. In the case of a full control region the sender is delayed on getting a free packet until the receiver acknowledged an old packet.
To do so, DSI uses counting semaphores. The current implementation features one semaphore per packet, two semaphores counting the free and allocated packets would be another possibility.
If a semaphore-counter at component A becomes -1 on decrement, the semaphore-imeplementation requests a free-IPC from component B at the other side of the connection. This is done by making an IPC-call with infitite timeout to a synchronisation thread running with B. If B realizes the blocking situation on an up-operation afterwards, it tells its synchronisation thread to answer the IPC-call with a free-IPC with timeout 0 back to A. The blocking situation is noticed atomically on the up-operation by B. In the case B notices the blocking situation before A did the IPC-call, the synchronisation thread waits for the IPC from A before sending its own free-IPC. This way it is ensured that the communication is working even on mutual untrusting components. All receive-IPCs are closed receives, and not sending an IPC only harms the component itself but not the peer.
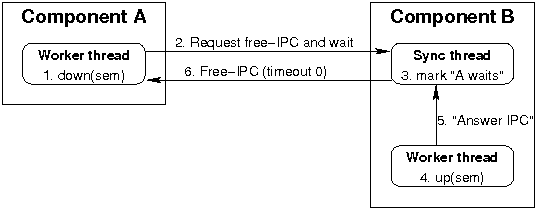
Communication on blocking semaphores
The downside of this implementation is that each connection requires one additional thread at both components. Another drawback is the additional IPC at B to the synchronisation thread, which could be ommited by extending the L4 interface with a 'send-as IPC' or a 'send-to-A receive-from-B IPC'.
In asynchronous mode, the receiver makes assumptions on the availability of new data based on a timebase and checks if this is the case. The sender works similar, it checks if there is free space in the control region for a new packet and possibly discards the data.
The asynchronous mode allows a sender to proceed with its work, independent of an potentially untrusted client. If the receiver does not acknowledge the data (and thus free the packet in the control region), it only hurts itself.
There a two different ways to handle a full control region resulting of unacknowledged data. One possibility is to discard the new data at the sender and not to withdraw the old packets. This means, if a receiver does not acknowledge old packets fast enought, it will miss new packets. This has the advantage, that a receiver can rely on the validity of a packet until it acknowleded it. But the data may be destroyed in between, think of a framegrabber card. The sender can mark this in the corresponding packet descriptor, so that the receiver is able to realize this. The other advantage of this approach is that packets are stored in-order in the control region. The tracking of the current packets is easy this way. This is the current implementation.
The other possibility is to overwrite old packets at the sender in the case of a full control region. This requires the receiver to check the validity of the data prior and after dealing with a packet. The advantage of this mode of operation is that a receiver can simply ignore a couple of packets if it is to slow. It always has the newest data available, the receiver does not need to acknowledge the old data to get the new one. This mode is currently not implemented. To support this mode, the DSI-API must provide the following functionality: The sender and the receiver must be able to specify a specific packet they want to get, even if it is out of order. DSI must allow to get a packet even if it is not free. DSI should provide functions to check if packets are valid/free and it should provide callbacks that are called if a packet is reclaimed.
To get a new packet in the control region use the dsi_packet_get() function. This works for sender and receiver aswell. The sender commits a packet after filling it with data with the dsi_packet_commit() function. Currently, the receiver uses the same function to free a packet after getting the data out of it. This may change to dsi_packet_acknowledge() in the future. For getting data in and out of a packet see the Data Transfer section.
This section deals with the consequences of the problem, that the synchronisation threads should only do a closed receive to prevent DoS attacks. The current implementation uses an open receive at the synchronisation thread.
The following discussion assumes two components, component L and component R, with L beeing blocked on R, because of waiting for signalling of packet N. The synchronisation thread of L is S, the worker thread of L is L and the worker thread of R is R.
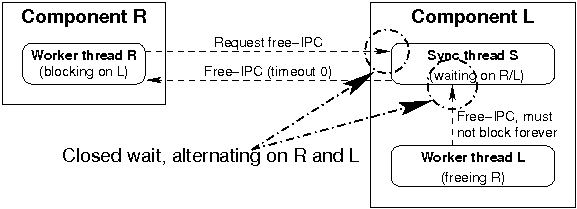
Local signalling
L must be aware of R to be potentially misbehaving. An attack of R is allowed to influence S but not L. R must rely on L: if R decided to wait anyway, it will tolerate silence of L, and wrong signaling by L is equivalent to sending wrong data or discarding data (depending on the direction of data flow). As a reminder, packets can be signalled in any order in the synchronisation region.
The closed receive requires S to wait on R, and only if the corresponding packet is not already signalled (which can be happened in between), S will wait for L then. Because L must not be blocked by misbehaving R, S must flag that it will wait for L. Signalling of N happens in a shared region with R, so L can be spoofed on this. To ensure L and S to have the same idea of the signalling and flagging state, L and S must use a private synchronisation mechanism. The easy solution is a blocking semaphore implementation, but there are faster ways.
We assume a maximum of p packets to be stored in the synchronisation region. A solution would be to have p fields containing an entry with the signalled packet and another entry with the IPC flag, both accessible by one atomic operation. S could atomically test the state and optionally set the flag. This downside of this solution is the additional field.
Another algorithm uses two variables, interest, and ipc. interest and ipc are placed in a way that they can be inspected and modified atomically. The worker thread L does the following steps:
- signal(N)
- atomically: if(interest == N) ipc = N
- if(ipc == N) send_ipc_to(S)
The synchronisation thread S does the following steps:
- interest = N
- if(not signalled(N)) ipc = N
- interest = 0
- if(ipc == N) rcv_ipc_from(L)
This algorithm works under the precondition that N is unique, this means, both the worker and the synchronisation thread do not execute this algorithm with the same N twice. While this can required for the work thread, the synchronisation thread must obtain it's N from the remote thread R, thus can be spoofed. A solution to this problem could be to reset ipc in a suitable way, e.g. by doing a long-ipc between L and S which atomically resets ipc to 0. The downside is the long-ipc.
The last algorithm tries to reset the ipc-variable in a safe way. Unfortunately, it is complicated and not proofed for correctness. The algorithm uses the four variables s_w, s_s, interest, and ipc. interest and ack are placed in a way that they can be inspected and modified atomically. The worker thread L does the following steps:
- N == s_w ? Error
- signal(N)
- atomically: if(interest == N) ipc = N
- if(ipc == N) {
- s_w = N
- send_ipc_to(S)
- if ( ipc == N) ipc = 0
- }
The synchronisation thread S does the following steps:
- N == s_s ? Error
- interest = N
- if(not signalled(N)) ipc = N
- interest = 0
- if(ipc == N) {
- s_s = N
- rcv_ipc_from(L)
- if(ipc == N) ipc = 0
- }
After that, the synchronisation thread S can safely send the unblocking IPC back to R (with timeout 0, of course).
