In order to evaluate the performance of the implementation, we built a
few benchmarks which we ran both on Mach and on L3 using our Mach
emulation library. 5.1 Measurement Environment
The version of Mach used was UK02pl13 from Utah University running Lites 1.1 (using a FreeBSD base system). On the L3 microkernel we used the standard L3 operating system.
Both operating systems ran on a 66 MHz 486-DX2 machine.
The tests were done when the systems were quiescent. On Mach, we used
the BSD time command to measure the programs. On L3, we used the
cputime ELAN procedure. 5.2 Message Passing Benchmark
5.2.1 Environment
In the first series of measurements, two tasks synchronously exchanged a number of Mach messages. Before doing so, each task created a port and copied a send right for the port to the other task.
In the first variation, the messages didn't carry any data. A second version exchanged some unstructured data between the tasks.
The third version was slightly more complicated: Both tasks allocated a number of ports, and sent send rights for these ports to the other task, which immediately deallocated the send rights it received.
In order to relativize the performance achieved by both Mach
environments (native and emulated), we also measured L3's raw IPC
performance directly using the L3 microkernel's message passing
primitives.
5.2.2 Results
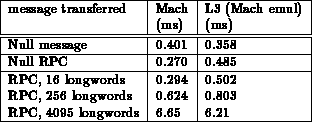
The following table summarizes the results. The times given are round-trip times for one message exchange.(1)
As can be seen from the table, for a simple message round trip (null message or message containing uninterpreted data), the mach_msg emulation on L3 is somewhat faster than Mach's mach_msg, while transferring port rights takes substantially longer in the emulated environment.
Sending uninterpreted data takes advantage of L3's highly optimized IPC path. According to [3], a ,,null RPC'' on L3 (implemented by two message transfers, i.e. in our context, a ,,null message'') can be up to twenty times faster than on Mach. (In our test, we observed a ratio of about 10 for small messages and 3 for larger messages.)
It is obvious that we can't achieve the same performance with our mach_msg emulation:
The performance penalty for transferring a port send right and deallocating it in the receiver on Mach is between about 55μs (for 256 rights) and 110μs (for 1 right), while on L3 it is between about 115μs (16 rights) and 165μs (1 right); in the 256 rights case, it is 140μs. (The round-trip penalties have been divided by 2.)
We attribute the extra cost on L3 to the distributed management of the port name space: To move a port right in the emulated environment, a corresponding port data structure needs to be looked up twice: once in the sender, and once in the receiver. In opposition to that, port right management is Mach is centralized in the kernel.
On Mach, manipulating port rights seems to become faster as more ports are to be manipulated at once. We don't know for sure why this happens; we suspect the kernel is building a cache working set when processing a long list of rights.
On L3, this effect is visible as well, to some degree. However, the transfer cost per port right for 256 ports is larger than for 16 ports. We know of two possible causes for this slowdown:
In this test, we used a simple client/server program where client and server (in separate tasks) communicate using MIG-generated RPC stubs. In the first version of this benchmark, the server procedure takes one integer argument which it passed back to the client (,,null RPC''). In the second version, an array of integer data is being copied back and forth between the client and the server.
Before starting, the server created a service port and communicated the
client a send right for it. Replies to the client were sent through
send-once rights generated from a reply port created by the MIG client
stub. This is MIG's standard way of setting up an RPC.
5.3.2 Results
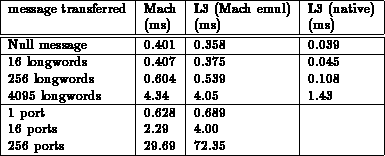
The following table summarizes the results. The times given are round-trip times for one RPC. The table also lists the times for the ,,null message'' benchmark from the previous section.
The first eye-catching result is that on Mach, a null RPC using MIG-generated stubs takes considerably less time than a simple message exchange even though an RPC seems to be doing more work: creating/destroying a send-once right, and the overhead added by the RPC stubs.
This is because the IPC path most commonly used by MIG-generated stubs (request using a send right, passing a send-once right for the reply, only uninterpreted data to transfer, i.e. no ports and no memory objects) has been specially optimized in the Mach kernel to reduce the number of context switches and the complexity of handling Mach-internal data structures. Our emulation library hasn't been optimized for this special case.
For mach_msg emulation on L3, the performance decrease compared to simple message passing seems to be about normal, given the cost of inserting and deleting the send-once right for the server's reply (about 165μs) and some extra cost for copying the data in the RPC stubs.
As can be seen from comparing the results of this and the previous
benchmark, RPC's transferring larger quantities of data between client
and server take longer than the respective message-passing variant in
both environments (and despite of the special RPC optimization in
Mach). This is due to extra copies of the transmitted data by the
MIG-generated RPC stubs.
5.4 Evaluation
The performance of our Mach emulation system lies within expected bounds: For many common cases, we achieve performance similar to or not dramatically worse than Mach. However, there is still room for a lot of optimization:
In the case of transferring a lot of port rights via Mach IPC, our emulation library performs notably worse than the original system. In section [here], we argumented against central port emulation in an external server, saying that this would require sending every message twice. It turned out, however, that the performance loss imposed by the decentral port emulation we implemented is much higher than the cost of an extra message copy. In Lites, sending port rights is a relatively rare operation, so that doesn't matter a lot. However, should a different project require Mach port emulation, this should be taken into consideration.