 Die Struktur der Mach-Singleserver-Emulation
Die Struktur der Mach-Singleserver-EmulationNeue Betriebssysteme und damit auch neue mikrokernbasierte Systeme stehen immmer wieder vor dem Problem, daß eine bestimmte Menge an Applikationen vorhanden sein muß, um eine gewisse Akzeptanz des Systems zu erreichen. Um dieses Ziel zu erreichen, werden verschiedene Wege gegangen, so zum Beispiel:
Im folgenden soll kurz auf die verschiedenen Varianten eingegangen
werden, wobei der Schwerpunkt auf die mit der Arbeit enger in
Verbindung stehende letzte Variante gelegt wird. 3.1.1 Neuimplementation von Anwendungen
Eine Neuimplementation von Anwendungen wird aus naheliegenden Gründen selten in Angriff genommen. Nur Systemhersteller mit einem entsprechenden finanziellen Hintergrund können es sich erlauben, Resourcen für ein solches Projekt freizumachen. Es ist nahezu unmöglich, alle für den Erfolg eines Systems notwendigen Applikationen, angefangen beim einfachen Editor, über Compiler bis hin zu komplexen Anwendungen wie Textverarbeitungen, Datenbanken und dergleichen mehr, in eigener Regie zu entwickeln. Steht eine entsprechend finanzkräftige Firma hinter dem System, wird in der Regel der Schwerpunkt auf einige wenige Applikationen, sogenannte Killerapplikationen gelegt, wie Textverarbeitung, Datenbank, Tabellenkalkulation u.a.m. Zusätzlich werden auf das System zugeschnittene Entwicklungswerkzeuge bereitgestellt, die anderen Firmen auf eine möglichst einfache und effektive Art und Weise die Entwicklung von Software für das neue System gestatten. Bei entsprechendem Engagement anderer Firmen entsteht dann die erforderliche Softwaredecke.
Entwicklungswerkzeuge für das System werden dabei in der Regel schon lange vor Fertigstellung des Produkts anderen Softwarefirmen zur Verfügung gestellt, um einen frühest möglichen Anlauf der Softwareproduktion zu gewährleisten.
Ein aktuelles Beispiel hierfür ist Microsoft und Windows 95. Lange
vor Erscheinen des Systems wurden ausgewählte Softwarefirmen mit
Betaversionen, Entwicklungswerkzeugen und Informationen über das
System versorgt, so daß nahezu alle namhaften Firmen bereits eine
auf Windows 95 abgestimmte Version ihrer wichtigsten Produkte in der
Schublade haben und kurz nach der Auslieferung mit dem Verkauf ihrer
Versionen beginnen können. Microsoft selbst wird ebenfalls kurz
nach Erscheinen von Windows 95 mit einer der wichtigsten Applikationen
für den normalen Anwender, mit der Office Suite auf dem Markt
präsent sein. Aber ein solches Herangehen ist nur bei
entsprechender Marktbeherrschung möglich.
3.1.2 Portierung von Anwendungen
Computer früherer Generationen hatten inkompatible Hardware- und Programmstrukturen, so daß Programme, die für ein bestimmtes System entwickelt worden waren, auf einem jedem System neu implementiert werden mußten. Ein erster Schritt zur Änderung dieser Situation hin zur Portabilität von Anwendungen war das System /360 von IBM, das ein einheitliches Betriebssystem auf verschiedenen, weitgehend binärkompatiblen Hardwareplattformen nutzte.
Im Jahre 1968 begannen die AT&T Bell Laboratorien mit der Entwicklung von UNIX. UNIX sollte die Nutzung eines einzigen Betriebssystems auf den verschiedensten Hardwareplattformen gestatten. Leider bildeten sich im Laufe der Zeit die verschiedensten UNIX-Versionen heraus, von denen mehr oder weniger keine Version kompatibel zur anderen war. Die heutigen UNIX-Varianten lassen sich in ihren Eigenschaften im wesentlichen auf die beiden Hauptlinien System V und BSD zurückführen. So war es letztendlich immer wieder eine Herausforderung, eine Anwendung zu schreiben, die auf den verschiedenen Plattformen lauffähig war.
Mit diesem Dilemma konfrontiert, bildeten die verschiedenen Hersteller ein Gremium, das sich mit dem Entwurf eines Hersteller-, Betriebssystem- und Architekturunabhängigen Standards für die Schnittstelle zwischen Anwendung und Betriebsystem bzw. Bibliothek befassen sollte. Dieses Gremium legte einen Entwurf vor, der 1988 in seiner ersten Version als ,,IEEE Standard 1003.1-1988 Portable Operating System Interface for Computer Environments'' (POSIX) verabschiedet wurde. Dieser wurde 1990 zu einem internationalen Standard und liegt nun in der zweiten Revision als IEEE Standard 1003.1-1993 vor.
POSIX-konforme Anwendungen lassen sich relativ leicht von einer Plattform auf die andere portieren, wobei selbst solche Systeme wie Windows/NT unterstützt werden. Nachteil dabei ist natürlich, daß POSIX nur eine Schnittmenge aus den bedeutendsten UNIX-Systemen (4.3BSD, System V) darstellt. Dadurch ist ein Entwickler immer wieder dazu gezwungen, auf Plattformspezifika einzugehen, die dann zusätzlichen Aufwand beim Portieren verursachen. Mit einem vernünftigen softwaretechnischen Entwurf lassen sich diese Systemabhängigkeiten allerdings kapseln, so daß im Idealfall nur diese Moduln re-implementiert werden müssen.
Trotz alledem stellt eine Portierung von Anwendungen einen recht hohen
Anspruch an die Entwickler und Portierer, weshalb dieser Weg auch nur
bei einer entsprechenden Wichtigkeit der Anwendung für das
Zielsystem beschritten wird. Beispiele hierfür sind die
UNIX-Standard-Werkzeuge, die auf nahezu jedem UNIX-System verfügbar
sind.
3.1.3 Binärkompatibilität zu einer anderen Plattform
Ein anderer Ansatz, gängige Softwarepakete verfügbar zu machen, ist die Bereitstellung eines Emulators für gebräuchliche Binärformate. Ein solches Format wird in der 'Intel Binary Compatibility Specification 2' (IBCS2) beschrieben. Dieser Standard definiert das Format ausführbarer Dateien und die Kommunikation der Anwendung mit dem Betriebssystemkern. Damit sollte es möglich sein, Anwendungen zwischen IBCS2-Systemen auszutauschen und ohne Neuübersetzung laufen zu lassen. Allerdings war die Spezifikation eingeschränkt und enthielt nicht alle heute gängigen Konzepte. Das führte dazu, daß jeder Hersteller die seiner Meinung nach fehlende Funktionalität hinzufügte und zwar auf die seiner Ansicht nach richtige Art und Weise. Das Ergebniß war eine Vielzahl inkompatibler IBCS2-Implementierungen.
IBCS2 definiert die Verwendung des Common Object File Formats (COFF) für Objektdateien, Programme und Shared Libraries. Leider ist die Unterstützung von Shared Libraries nur sehr rudimentär ausgeprägt. Es werden Bibliotheken mit fest vorgegebenen Einsprungadressen verwendet. Features wie dynamisches Linken, Position independent Code und andere heute übliche Techniken werden nicht unterstützt.
Eric Youngdale beschreibt in [8] die Realisierung einer IBCS2-Emulation auf Linux. Die Emulation ging von der Implementierung des IBCS2-Standards auf SVR3 aus, die als Referenzimplementierung angesehen wurde, und realisierte in einem ersten Schritt eine Emulation für SCO Binaries. Heute können zusätzlich SVR4 und Wyse Binaries ausgeführt werden. Die Probleme, die dabei zu lösen waren, lassen sich im wesentlichen wie folgt zusammenfassen:
Unter den System V-Abkömmlingen existiert das Konzept der Streams. Sie werden von Linux nicht unterstützt, und der Aufwand, Streams zu emulieren, wurde als zu hoch eingeschätzt. Stattdessen wurden für spezielle Verwendungszwecke, wie Netzzugriff oder Kommunikation mit dem X-Server, spezielle Emulationsmimiken eingeführt.
Ein oft gewählter Weg ist die Emulation der Plattform, auf der die gewünschten Applikationen zur Verfügung stehen. Häufig wird eine UNIX-Schnittstelle emuliert, da für UNIX als gewachsenem Betriebssystem eine Vielzahl sowohl kommerzieller als auch frei verfügbarer Applikationen existieren, die zur Entwicklung eingesetzt werden können. Somit lohnt es sich, die Schnittstellen dieses Systems nachzubilden, um auf einfache und elegante Art und Weise eine breite Softwarepalette zu erschließen. Hinzu kommt, daß es bei der unter UNIX frei verfügbaren Software üblich ist, den Quelltext mit auszuliefern. Dadurch ist es im Falle eines Fehlers in der Anwendung oder in der Implementation der UNIX-Semantik einfacher, den Fehler nachzuvollziehen und zu lokalisieren. Das ist bei Verwendung von binären Dateien nicht ohne weiteres möglich. Die bekanntesten Vertreter sind hier die verschiedenen in der Literatur beschriebenen UNIX-Implementationen auf Mikrokernen [1] [2] [3] [9] [5] . Auf einige ausgewählte Emulationen, den Mach-Singleserver, den Mach-Multiserver und die Emulation auf Spring, wird im Laufe des Kapitels noch eingegangen.
Ein Vertreter einer anderen Richtung ist WABI. Schon bald nach dem
Erscheinen von Windows 3.0 gab es bei verschiedenen Herstellern
Bedenken gegenüber der sich abzeichnenden Marktdominanz von Microsoft und
der Fülle der für diesen Betriebssystemaufsatz geschriebenen
Anwendungen. Hier ging eine gewaltige Masse an potentiellen
UNIX-Anwendern verloren, da durch die in enormem Maße anwachsende
Installationsbasis von Windows eine Vielfalt an Applikationen
entstand, die aufgrund der Menge installierter Windows-Versionen für
auch den finanzschwachen Anwender nutzbar war. Um diese Softwarebasis für
sich zu erschließen und damit gleichzeitig etwas gegen die Dominanz
von Microsoft zu tun, entwickelte Sun-Micro Systems bzw. die für
Betriebssysteme zuständige Tochterfirma Sun-Select das Windows
Application Binary Interface. Es emuliert ein Windows 3.1 im
Standardmodus und gestattet dadurch die Abarbeitung von
Windows-Applikationen auf einer Sun-Workstation, indem es im
einfachsten Falle auf einem Intelprozessor die Windows-API-Aufrufe auf
die entsprechenden X-Windows-Aufrufe umsetzt bzw. auf nicht
Intel-Prozessoren einen 80286 emuliert.
3.2 Verschiedene UNIX-Implementationen auf Mikrokernen
Im universitären Umfeld ist UNIX das am häufigsten eingesetzte Betriebssystem. Hier ist eine breite Menge an Software vorhanden, die auf dieses System zugeschnitten und in der Regel auch frei verfügbar ist. Hinzu kommt, daß die Entwickler der im folgenden besprochenen Emulationen in der Regel an der Entwicklung einer UNIX-Variante direkt oder indirekt beteiligt waren und dadurch Erfahrung in der Implementation von UNIX bzw. direkten Zugriff auf die Quellen einer solchen hatten.
In den nächsten Abschnitten sollen verschiedene UNIX-Implementationen
auf Mikrokernen betrachtet werden, die die UNIX-Semantik innerhalb
eines oder mehrerer normaler Nutzerprozesse realisieren. Am Ende des
Kapitels wird versucht, eine Übersicht über die wesentlichen
Gemeinsamkeiten und Unterschiede zu geben. 3.2.1 Der Mach-Singleserver
Überblick
In [1] wird eine der ersten UNIX-Implementationen auf User-Level beschrieben. Die Autoren folgten damit einem sich schon lange abzeichnenden Trend in der Informatik, dem Ansatz, Applikationen nach dem Client/Server-Modell zu entwerfen. Verteilte Dateisysteme, Namensdienste und Datenbanken waren der erste Schritt, ein nach dem gleichen Modell entworfenes Betriebssystem die logische Schlußfolgerung. Dabei zeichneten sich neben den offensichtlichen Vorteilen des Client/Server-Ansatzes folgende Vorteile ab:
Der Anwender des Betriebssystems kann sich sein UNIX oder ein anderes Betriebssystem nach seinen Anforderungen aussuchen. Er kann entscheiden, ob er ein BSD, System V oder POSIX auf seiner Zielplattform verwendet. Durch eine Kombination eines abstrakten Servers oder verschiedener Server und entsprechenden Emulationsbibliotheken ist es auch möglich, mehrere konkurierende Systeme laufen zu lassen.
Die Implementation des Betriebssystems ist nahezu vollständig hardwareunabhängig. Die Hardwareeigenschaften werden bis auf wenige Ausnahmen vom darunterliegenden Mikrokern und den Gerätetreibern gekapselt.
Aufgrund der inhärenten Netzwerkfähigkeit des Systems konnte der UNIX-Server auf einem anderen Rechner laufen, als seine Klienten. Da in diesem Falle aber durch das Netz relativ hohe Nachrichtenlaufzeiten entstehen, dürfte diese Eigenschaft eher von theoretischem Interesse sein.
Da die UNIX-Server unabhängig vom Kern in einem eigenen Adreßraum liefen, war es sehr einfach, eine neue Version oder ein API (Application Programming Interface) einer anderen UNIX-Version zu implementieren und zu testen.
Ein monolithisch implementiertes UNIX hat in der Regel lange Kodepfade im Kern, in denen es nicht unterbrochen werden kann. Es schützt dadurch auf recht einfache Art und Weise seine Systemdatenstrukturen. Implementiert man UNIX aber außerhalb des Kerns, entfallen solche langen, nicht unterbrechbaren Pfade im Kern, was zu verbesserten Echtzeiteigenschaften führen kann.
Die UNIX-Emulation besteht aus zwei Komponenten, dem UNIX-Server, der einen Großteil der UNIX-Semantik bereitstellt, und der Emulationsbibliothek, die sich der Dienste des Servers bedient, um die UNIX-API zu implementieren. Für die Realisierung dieser beiden Komponenten werden laut [1] folgende Mach-Konstrukte verwendet:
Aktive Einheiten unter Mach werden als Threads bezeichnet. Threads repräsentieren Kontrollflüsse innerhalb einer Task, die ihrerseits einen Adreßraum darstellt. Threads kommunizieren über Ports, die vom Kern geschützt werden. Um an einen Port senden oder etwas von einem Port empfangen zu können, muß man ein entsprechendes Sende- oder Empfangsrecht besitzen. Dieses Recht erhält man beim Erzeugen des Ports, kann es aber auch weiterreichen oder von anderen erhalten. Die Rechte werden der Task zugeordnet, die damit als Schutzdomäne fungiert. Gleichzeitig können Senderechte als Capability Verwendung finden, da die Senderechte vom Kern verwaltet und damit nicht gefälscht werden können.
Mach-Kernobjekte werden durch Ports repräsentiert. Um ein solches Objekt, eine Task, einen Thread oder ein Memory-Object zu manipulieren, muß man eine Nachricht an den entsprechenden Port senden. Damit wird der Schutz der Kernobjekte durch das Schutzkonzept der Ports realisiert.
Mach führte als eines der ersten Betriebssysteme das Konzept des externen Pagers ein. Die Funktion des Kerns reduziert sich dabei auf das Einblenden eines Memory Objects in den Adreßraum und das Puffern seines Inhaltes im physischen Speicher. Wird auf einen Teil eines solchen Objektes zugegriffen, das sich nicht im Speicher befindet, wird eine Nachricht an den das Objekt repräsentierenden Port gesendet. Der hinter dem Memory Object stehende Pager sorgt dann für den Transfer der Daten in den Speicher.
Hervorzuheben ist noch die Möglichkeit, Systemrufe umzulenken. Es ist
auf Mach möglich, eine bestimmte Menge von Systemrufen und
Unterbrechungen zu definieren, die vom Kern an die rufende Task
zurückgereicht und dort behandelt werden. Das gestattet auf einfache
Art und Weise, einen bestimmten Systemruf oder eine
Unterbrechungsbehandlung auf User-Level zu implementieren. Für eine
genauere Beschreibung der anderen Eigenschaften sei auf [1] und [10]
verwiesen.
Die Realisierung
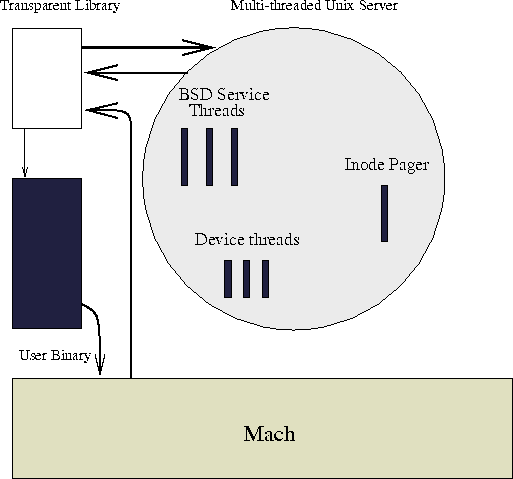
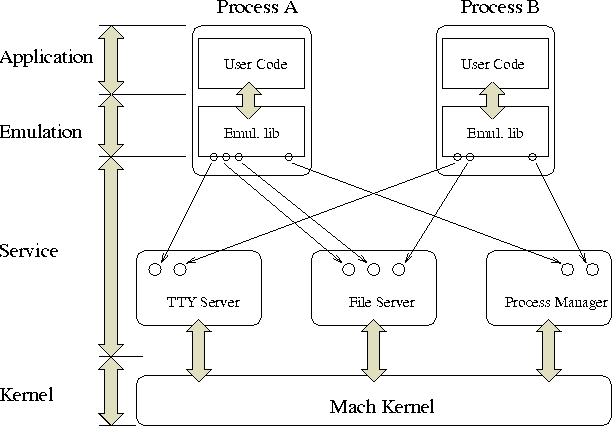
Die in Abbildung [hier] dargestellte Struktur des Singleservers ist aus [1] entnommen. Wie zu sehen ist, besteht die Emulation aus zwei Teilen, der transparenten Bibliothek und dem UNIX-Server. Dieser wird als Singleserver bezeichnet, da er die ganze UNIX-Funktionalität in einer einzelnen Task realisiert, also quasi einen monolithischen Kern auf User-Level darstellt. Im folgenden sollen die einzelnen Teile etwas näher beleuchtet werden.
Die Struktur der Mach-Singleserver-Emulation
Die Kommunikation zwischen dem UNIX-Server und dem UNIX-Prozeß findet in der Regel über IPC statt. Wird für die Realisierung eines UNIX-Systemrufs der Dienst des UNIX-Servers benötigt, wird von der Emulationsbibliothek eine Nachricht an den entsprechenden Port gesendet. Auf der Serverseite wird dann aus einem der Pools ein Thread entnommen, der den geforderten Dienst erbringt.
In einigen speziellen Ausnahmen wird aus Effizienzgründen auf einen anderen Mechanismus zurückgegriffen. So wird bei der Implementation der UNIX-Dateien auf den External-Pager-Mechanismus zurückgegriffen. Ein spezieller Thread innerhalb des Singleservers, der I-Knoten-Pager, stellt Dateien als memory objects bereit. Wird eine Datei geöffnet, wird sie direkt in den Adreßraum des UNIX-Prozesses gemappt. Greift dieser dann in einer Read/Write-Operation darauf zu, werden die daraus resultierenden Forderungen an den I-Knoten-Pager geleitet, der die benötigten Daten bereitstellt. Um die UNIX-Semantik des File-Sharings zu realisieren, synchronisiert die Emulationsbibliothek in kritischen Fällen den Zugriff auf die gemappte Datei mit dem Fileserver.
Die Emulationsbibliothek wird beim Erzeugen des ersten UNIX-Prozesses (in der Regel init) in den Adreßraum der Task gemappt und weist in der Initialisierungsphase den Mach-Kern an, UNIX-Systemrufe an eine in der Bibliothek befindliche Behandlungsroutine umzuleiten. Dieser analysiert die Register und ruft eine entsprechende Funktion auf. Kann die Emulationsbibliothek den Dienst selbst erbringen, wie z.B read, write auf gemappte und nicht gesharte Dateien oder Modifikation von Statusinformationen, die den Server nicht interessieren, verzichtet sie auf einen Aufruf des Servers. Ist das nicht möglich, wird aus den Parametern des Systemrufs und eventuellen Zusatzinformationen eine Nachricht generiert und an den UNIX-Server gesendet. Die zurückkommenden Resultate werden an den Aufrufer zurückgegeben.
Die Emulationsbibliothek und das Umleiten der Systemrufe werden bei einem fork()-Systemruf durch Mach automatisch an den neuen Prozeß vererbt. Damit kann dieser ohne sein Zutun sofort als UNIX-Prozeß agieren. Ähnlich verhält es sich beim Ausführen eines execve()-Systemrufs. Hier wird durch die Bibliothek nur der UNIX-Adreßbereich ausgetauscht, so daß sie dem neuen Programm sofort wieder zu Verfügung steht.
Zwei Dinge wurden bei der Implementation der Bibliothek besonders beachtet. Zum einen verwendet die Bibliothek einen eigenen Stack, um dem Nutzer eine eigene Stackverwaltung zu ermöglichen. Das wird z.B. für die Realisierung einer eigenen Threadimplementation benötigt. Zum anderen ist die Bibliothek dadurch, daß sie sich im Adreßraum des UNIX-Prozesses befindet, absichtlichen Angriffen oder versehentlichen Zugriffen ausgesetzt. Das mußte bei der Implementation des Servers berücksichtigt werden, der sich auf Informationen der Bibliothek nicht verlassen darf, da sie fehlerhaft sein können. Zum anderen müssen die Informationen in der Bibliothek korrumpiert weden dürfen, ohne daß die Fuktionalität der anderen Prozesse und des Gesamtsystems beeinträchtigt wird.
Während der Realisierung der Emulation wurden laut [1] festgestellt, daß folgende Punkte Einfluß auf die Effizienz der Emulation haben:
Hier wurden verschiedene Optimierungen vorgenommen, wie die oben erläuterte Realisierung der Dateizugriffe.
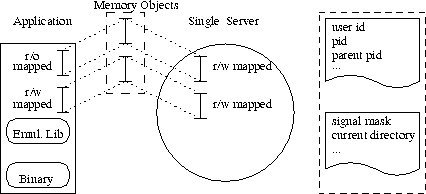 Geteilte Speicherbereiche zur Verwaltung von Prozeßzuständen
Geteilte Speicherbereiche zur Verwaltung von Prozeßzuständen
Zur Verbesserung der Effizienz solcher relativ häufig genutzter Dienste wie getpid(), sig<...>(), die Statusinformationen verändern, wurden Speicherbereiche eingeführt, die zwischen Server und Emulationsbibliothek geteilt werden. Da dabei Sicherheitsaspekte berücksichtigt werden müssen, wurden ein read only und ein read write gemappter Speicherbereich eingeführt, über den beide Informationen austauschen können (s. Abbildung [hier]).
Ein noch nicht zur Zufriedenheit gelöstes Problem blieb das Prozeßmanagement. Die Architektur der Emulation, Trennung in transparente Emulationsbibliothek und UNIXprogramm mit separatem Stackbereich, führt in Verbindung mit dem copy on write-Vererben zu einer höheren Anzahl von Seitenfehlern, was in einer schlechteren Leistung (3 mal langsamer) im Vergleich zur monolithischen Implementation resultiert.
Einige dieser Probleme wurden in dem auf dem Mach-Singleserver
aufbauenden Lites-Singleserver[11] gelöst. In
Anbetracht der Tatsache, daß die wenigsten UNIX-Programme Gebrauch von
den Möglichkeiten der Stackmanipulation machen, arbeitet die
Emulationsbibliothek auf dem Nutzerstack. Ein anderer interessanter
Aspekt ist der komplette Austausch der Emulationsbibliothek beim
Ausführen eines Programms, durch das dem Nutzer mehr Rechte
zugestanden werden. Im Mach-Singleserver ist es laut Helander möglich,
den Bereich der Emulationsbibliothek zu modifizieren und danach ein
Programm auszuführen, das mit Root-Rechten verbunden ist. Diese
Möglichkeit wurde mit dem Austausch der Bibliothek unterbunden.
3.2.2 Die Spring-UNIX-Implementation
Sun-Microsystems entwickelten im Rahmen der Forschung ein
mikrokernbasiertes Betriebssystem namens Spring. Anhand von Spring
sollten Fragen betrachtet und beantwortet werden, die sich aus dem
allgemeinen Trend weg vom monolithischen und hin zum Mikrokern
ergeben. Spring ist als objektorientiertes, verteiltes und auf einem
Mikrokern basierendes Betriebssystem entworfen worden. Es soll im
folgenden kurz betrachtet werden, wobei nach einer kurzen Einführung
speziell auf die Implementation der UNIX-Emulation eingegangen wird. Überblick über Spring
Spring wurde auf der Basis von Objekten entworfen, d.h., es unterstützt die Implementation von Anwendungen mit objektorientierten Ansätzen. Ein Objekt in Spring ist eine Abstraktion, die einen Status und eine Menge von Methoden besitzt. Diese Methoden werden mit einer objektorientierten Interface Definition Language (IDL) beschrieben, die auch das Vererben von Schnittstellen unterstützt, wobei sowohl einfache als auch mehrfache Vererbung möglich sind. Spring lehnt sich dabei soweit an objektorientierte Sprachen an, daß eine Schnittstelle, die ein Objekt vom Typ bar akzeptiert, auch ein Objekt einer Subklasse von bar akzeptiert. Auf diese Weise wird zum Beispiel das Mappen von Dateien realisiert. Dateien erben von der Klasse memory_object, die in den Adreßraum gemappt werden kann.
Das Äquivalent des UNIX-Prozesses wird in Spring als Domäne bezeichnet. Eine Domäne ist ein Adreßraum mit einer Menge von Threads. Sie kann als Server für andere Domänen oder als Klient anderer Domänen fungieren. Um Dienste anderer Domänen in Anspruch nehmen zu können, ist eine Möglichkeit der Interprozeßkommunikation notwendig. Diese stellt der Spring-Kern mit den Doors bereit.
Eine Door ist ein Einsprungpunkt einer Domäne und stellt ein vom Kern geschütztes Objekt dar. Will ein Thread einen Dienst einer anderen Domäne anfordern, muß er sich zuerst Zugriff auf eine Door dieser Domäne verschaffen. Hier gilt ähnliches wie in Mach, Rechte an einer Door können weitergegeben werden. Eine Door ist im wesentlichen eine virtuelle Adresse und ein Identifikator für ein referenziertes Objekt. Wird ein Call auf eine solche Door ausgeführt, führt das zu einem Transfer des Kontrollflusses in die andere Domäne zur in der Door angegebenen Adresse. Der Identifikator des referenzierten Objektes wird dabei in einem Register übergeben. Der Kern speichert bei diesem Aufruf alle notwendigen Informationen, um nach Beendigung des Aufrufs wie nach einem normalen Prozeduraufruf zum Klienten zurückzukehren. Für eine genauere Beschreibung dieses Mechanismus sei auf [12] verwiesen.
Objekte können in Spring an Namen gebunden werden. Diese Namensbindung wird durch Kontextobjekte realisiert, die durch Nameserver implementiert werden. Da Kontextobjekte wie jedes andere Objekt benannt werden können, ist auf einfache Art und Weise möglich, eine Namenshierarchie aufzubauen, die sich über mehrere Server erstreckt [13].
Desweiteren unterstützt Spring Mechanismen für Speichermapping (memory mapping) und Management des physischen Speichers.
Spring wurde als verteiltes System entworfen. Es unterstützt einen transparenten Aufruf eines Objektes über Rechnergrenzen hinweg. Die Transparenz dieser Zugriffe wird dabei ähnlich wie in Mach (NetMsg-Task) durch einen Proxy-Agenten gewährleistet. Der Spring-Kern selbst weiß nichts über andere, auf anderen Rechnern befindliche Kerne.
Abbildung [hier] stellt eine typische Spring-Konfiguration dar. Sie besteht aus dem Kern, der nur Domänen und Threads und elementare Dienste zu ihrer Behandlung bereitstellt, und diversen Servern, die die restliche, betriebssystemspezifische Funktionalität erbringen. Auf einem typischen Spring-Rechner laufen:
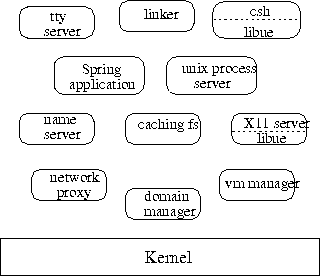 Eine typische Spring Konfiguration
Eine typische Spring Konfiguration
Die UNIX-Emulation
Spring war wie jedes andere neue Betriebssystem mit dem in Kapitel [hier] beschriebenen Applikationsproblem konfrontiert. Die Realisierung einer UNIX-Emulation auf Spring sollte zum einen dieses Problem lösen, und zum anderen die Eignung des Spring-Designs für größere Projekte unter Beweis stellen. Die UNIX-Emulation wurde laut [5] mit einem Aufwand von etwa einem Mannjahr bearbeitet und realisiert etwa 60% der Sun-OS-Funktionalität. Die grundlegenden Designentscheidungen sollen in diesem Abschnitt betrachtet werden.
UNIX-Objekte werden in der Regel über Deskriptoren referenziert. Diese Deskriptoren stellen Indizes in einer Tabelle dar, in der die Informationen über das referenzierte Objekt verwaltet werden. Um hier einen möglichst flexiblen Ansatz zu realisieren, wurde eine allgemeine Klasse Deskriptor(1) entworfen, die generische Methoden für Lesen, Schreiben, Beschaffen von Statusinformationen u.a.m. bereitstellt. Für die meisten UNIX-Objekte reichten diese Methoden aus. Sonst konnte das Verhalten des Objektes mittels Vererbung modifiziert werden. Die Deskriptortypen werden von der Emulationsbibliothek bereitgestellt, die dahinterstehenden Objekte vom Server oder von Spring implementiert. Eine Übersicht über die Typen und Objekte kann [5] entnommen werden.
Über die Zuordnung der Daten zur Bibliothek bzw. zum UNIX-Objekt wurde anhand eines einfachen Kriteriums entschieden: Dürfen die Daten vom UNIX-Prozeß modifiziert werden, ohne daß dadurch andere Prozesse oder Server beeinträchtigt werden, gehören sie in die Bibliothek. Informationen, die nicht verändert werden dürfen, kommen in das UNIX-Objekt.
Wie in den vorangegangenen Ausführungen bereits angedeutet wurde, besteht die UNIX-Emulation neben den Spring-Objekten aus zwei Hauptbestandteilen, dem UNIX-Server und der Emulationsbibliothek.
Der Server realisiert diese Funktionen, indem er entsprechend der Philosophie von Spring Objekte bereitstellt. Das wichtigste Objekt ist das UNIX-Prozeß-Objekt. Es existiert pro UNIX-Domäne genau einmal, wird im Rahmen der fork()-Operation erzeugt und der Domäne zur Verfügung gestellt. Mit Hilfe des Objektes werden dem Prozeß seine Identität und seine Resourcen zugeordnet. Es stellt im Rahmen seiner Methoden alle zur Realisierung der UNIX-Semantik notwendigen Dienste zur Verfügung. Diese lassen sich in vier Kategorien einteilen:
Führt ein Klient eine Operation auf einem solchen UNIX-Objekt aus, weiß der Server aufgrund des Aufrufmechanismus, von welchem UNIX-Prozeß der Ruf kam, und kann entscheiden, ob die Operation zulässig ist. Reserviert ein UNIX-Prozeß durch einen Aufruf einer Methode des UNIX-Objektes eine Resource, wird sie dem UNIX-Objekt zugeordnet, wodurch ein genauer Überblick über Eigentumsverhältnisse möglich wird. Solche Aufrufe sind:
Operationen auf dem UNIX-Objekt führen in der Regel zu einem Aufruf eines Serverdienstes über eine Door. Der Kern führt mit Hilfe eines Referenz-Zählers Buch über die Anzahl der Domänen, die Zugriff auf eine Door haben[12]. Beendet eine Domäne ihre Existenz, gibt sie den Zugriff auf die Door auf und der Zähler wird um eins verringert. Wird eine Door nicht mehr referenziert, erhält der zugehörige Server eine Nachricht und kann entsprechend reagieren.
Beendet ein UNIX-Prozeß seine Arbeit auf normale Art und Weise mit exit(), erfährt der UNIX-Server durch den Aufruf der entsprechenden Methode des UNIX-Prozeß-Objektes davon. Es gibt jedoch Situationen, in denen sich ein UNIX-Prozeß durch einen Programmfehler oder durch böswillige Absicht, ohne exit() zu rufen, beendet. Dann erfährt der UNIX-Server durch den Referenz-Mechanismus spätestens beim Beenden des letzten Klienten, der Zugriff auf die bereitgestellten Resourcen hat, vom Ende des Prozesses. Er kann dann die belegten Resourcen freigeben.
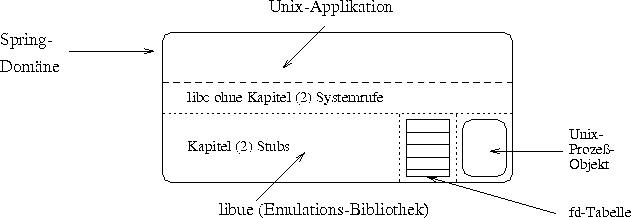 Eine UNIX-Applikation unter Spring
Eine UNIX-Applikation unter Spring
Wie in Abbildung [hier] zu sehen ist, besteht die Emulationsbibliothek im wesentlichen aus den folgenden Bestandteilen:
Die Bibliothek `libue' wird beim Laden des Programms anstelle der `libc' dynamisch hinzugebunden. Sie ist bis auf die Kapitel (2) Systemaufrufe, die durch die eigenen Stubs ersetzt wurden, identisch mit der `libc'. Da Spring-UNIX-Applikationen immer dynamisch gebunden werden, kann man auf einen speziellen Mechanismus wie die Systemruf-Umleitung in Mach verzichten.
Allerdings mußte an dieser Stelle eine Erweiterung des Binders vorgenommen werden.
Ein normales UNIX-Programm besteht aus einem Startupkode, dem eigentlichen Programm und den verschiedenen Bibliotheken. Die Bibliotheken zu binden, ist die eigentliche Aufgabe des Binders. Für die Emulation wurde ein spezieller Startupkode benötigt, der zusätzlich zum Aufruf des Bindens einige Initialisierungen vornimmt, die vom normalen Startupkode nicht vorgenommen werden. Deshalb wurde der Binder so erweitert, daß er in der Lage war, eine zusätzliche Bibliothek vor das eigentliche Programm zu linken und damit den Standardstartupcode durch den emulationsspezifischen zu ersetzen. Der Binder liefert als Ergebnis eines Aufrufs ein Menge von Tripeln (memory_object, adresse, länge), die in den Adreßraum der UNIX-Domäne gemappt werden.
Beim Aufruf eines select() wird als erstes auf Deskriptoren geprüft, die ready sind. Ist das nicht der Fall,wird für jeden Deskriptor ein Thread erzeugt, der auf das Bereitwerden wartet. Ein zusätzlicher Thread überwacht das Ablaufen der Zeit. Wird ein Deskriptor bereit oder kommt ein Timeout, wacht ein Thread auf, markiert einen evtl. bereitgewordenen Deskriptor als ready und der select()-Ruf kehrt zurück. Die anderen Threads schlafen weiter für den Fall, daß der select()-Ruf noch einmal aufgerufen wird, und ein Deskriptor in der Zwischenzeit bereit wird.
Der Mach-Multiserver, respektive das Mach 3.0 multi-server emulation system, ist ein Produkt eines Projekts der Carnegie Mellon University , das sich mit der Erstellung eines allgemeinen Frameworks für die Emulation von Betriebssystemen befaßt. Auslöser für dieses Projekt waren die zunehmenden Aktivitäten der verschiedensten Gruppen, auf Mach ein anderes Betriebssystem zu emulieren, angefangen bei solchen Systemen wie MS-DOS[14] bis hin zu komplexen Systemen wie VMS. Alle diese Emulationen hatten grundlegende Designentscheidungen gemeinsam. Die Emulation basierte in der Regel auf einem oder mehreren Servern, die von einer Emulationsbibliothek genutzt wurde, um die API des Zielsystems bereitzustellen. Die Funktionen dieser Bibliotheken waren sich sehr ähnlich, unabhängig vom emulierten Betriebssystem. Hier eine allgemeine Basis zu finden, die einen weiten Bereich an Emulationen abdeckt, ist das Ziel dieses Projekts. Man versprach sich von einem allgemeineren Ansatz höhere Modularität, Portabilität, Flexibilität, Sicherheit und Erweiterungsfähigkeit. Zusätzlich erhoffte man sich aufgrund der Modularität einen einfacheren Entwicklungszyklus, eine einfachere Wartung und Fehlerbeseitigung.
Das im Rahmen des Designprozesses entworfene Framework besteht aus verschiedenen generischen Servern, die auf User-Level laufen und die für die Emulation der verschiedenen Systeme erforderlichen Dienste auf einem möglichst abstrakten Niveau bereitstellen. Innerhalb des Projekts wird versucht, die dabei entstehenden Probleme zu untersuchen und Lösungen dafür zu finden. Dabei wurden unter anderem folgende Punkte betrachtet:
Um die getroffenen Designentscheidungen verifizieren zu können, wurde eine Emulation auf diesen Grundlagen implementiert. Ausgewählt wurde dazu ein UNIX 4.3BSD, mit dem in vorangegangenen Projekten schon intensive Erfahrungen gesammelt wurden [1].
In diesem Abschnitt wird versucht, einen Überblick über die
Struktur des Mach-Multiservers sowie die Konzepte und deren Umsetzung zu
geben. Die Struktur des Mach-Multiservers
 Die Struktur des Mach-Multiservers
Die Struktur des Mach-Multiservers
Die Struktur der Emulation ähnelt der in Kapitel [hier] beschriebenen Singleserver-Emulation.
Der Mach-Kern stellt lediglich die elementaren Mach-Primitive bereit. Er wurde in keiner Art und Weise für die Emulation erweitert.
Der UNIXprozeß ist eine Kombination aus Binary und Emulationsbibliothek, die pro Prozeß in einer separaten Task laufen. Die Emulationsbibliothek fängt mit Hilfe der Systemruf-Umleitung die UNIX-Systemrufe ab und behandelt sie entsprechend ihrer Semantik. Dabei wird versucht, einen größtmöglichen Teil der Funktionalität in der Bibliothek selbst zu erbringen. Wo das nicht möglich ist, wird die Hilfe der Server in Anspruch genommen. Sie erbringen den fehlenden Teil der Funktionalität. Ihre Schnittstellen sind dabei so allgemein gehalten, daß sie von einer Vielzahl verschiedener Emulationsbibliotheken genutzt werden können.
Die Kommunikation zwischen Emulationsbibliothek und Servern erfolgt
primär über Mach-IPC. In bestimmten Fällen, wie z.B. beim
Dateizugriff, wird aus Gründen der Effizienz auf das Mappen
von Dateien bzw. auf das Sharen von Speicherbereichen zwischen
Emulationsbibliothek und Server zurückgegriffen. Diese speziellen
Mimiken werden mit Hilfe des Mach-Konzeptes External Pager
realisiert.
Entwurf des Emulations-Frameworks
Beim Entwurf des Frameworks wurden zwei Schichten definiert,
Der Service Layer besteht aus Servern, die so generisch wie möglich entworfen werden. Im Idealfall sind es kleine Einheiten, die jeweils eine klar überschaubare, möglichst allgemeine Abstraktion anbieten, so daß ihre Dienste von einer großen Vielfalt von Emulationen genutzt werden kann. Beispiele hierfür sind
Der Emulation Layer ist in der Regel eine Emulationsbibliothek, die dem Entwickler die Schnittstelle des emulierten Systems zur Verfügung stellt. Er bildet dabei die allgemeinen Schnittstellen der Server auf die spezielle Programmierschnittstelle des Systems ab.
Die Schnittstelle zur Anwendung hin ist vom emulierten System vorgegeben. Die Schnittstelle zwischen dem Emulation Layer und dem Service Layer kann jedoch frei definiert werden, da sie nach außen hin nicht sichtbar wird. Bei ihrem Entwurf wurde deshalb Wert auf Schnelligkeit, Robustheit, Flexibilität und Sicherheit gelegt.
Der Ansatz, möglichst allgemeine Server zu entwerfen, ließ sich
jedoch nicht konsequent durchsetzen. Es zeigte sich, daß es in
nahezu jedem zu emulierendem System Eigenheiten gibt, die die
Implementation spezieller Server erfordert. Beispiele dafür sind
das Prozeßmanagement, die Authentifizierung und die
Terminalbehandlung, die von den Systemen verschieden gehandhabt
werden. So wurde darauf verzichtet, einen allgemeinen Terminal-Server
zu bauen, da die Terminalfunktionalität in UNIX sehr komplex
ist. Hinzu kommt, daß die Terminalfunktionalität eng mit der Prozeßverwaltung
verwoben ist. Vom Terminal werden z. B. Signale generiert, die eng mit
der Verwaltung von Prozeßgruppen zusammenhängen, die wiederum vom
Prozeßserver implementiert werden.
Schnittstellen
Die Operationen über den von den Server bereitgestellten Objekten lassen sich in allgemeine Gruppen zerlegen: Zugriffskontrolle, Namensverwaltung, I/O, Netzwerkdienste und Weiterleitung asynchroner Ereignisse. Wie aber leicht zu erkennen ist, läßt sich kein Objekt lediglich mit Funktionen einer dieser Gruppen realisieren. Über einer Datei müssen sowohl Zugriffskontrolle als auch I/O-Operationen möglich sein. Deshalb erfolgt die Bildung der Schnittstelle eines Objektes immer durch eine Kombination von Schnittstellen der verschiedenen Gruppen.
Beim Design der Schnittstellen wurden folgende Richtlinien beachtet:
Dabei mußten aber folgende Nebenbedingungen beachtet werde:
Die Erbringung eines Dienstes erfolgt nach dem Client/Server-Modell. Für den Zugriff auf den Dienst eines Servers wurde hier eine spezielle Möglichkeit geschaffen, das sogenannte Remote Message Invocation (RMI) Interface. Es kapselt die Art und Weise des konkreten Zugriffs auf ein Objekt und bietet Eigenschaften wie
Neben einer Standardkommunikation, die Mach-IPC nutzt, können für jedes Objekt spezielle Kommunikationsmechanismen implementiert werden, die z. B. Shared Memory oder Pufferung einsetzen.
Die Details der Implementierung bleiben dem Nutzer verborgen und können sich jederzeit unter Beibehaltung der Schnittstellen ändern.
Einige Betriebssysteme (z. B. UNIX) lassen eine asynchrone Unterbrechung eines Systemaufrufs zu. Hier wurde ein Mechanismus geschaffen, der es erlaubt, einen Call zu einem Server abzubrechen.
RMI realisiert eine transparente Kontrolle der Zugriffsrechte auf das Objekt, für das ein Dienst gefordert wird, und eine Bereitstellung der Id des Aufrufers. Es ist nicht möglich, unberechtigt auf ein Objekt zuzugreifen oder seine Id zu fälschen.
Der das Objekt bereitstellende Server hat keine Information darüber, wieviele Klienten auf ein Objekt zugreifen, aber er erfährt, wenn kein Klient mehr eine Referenz auf das Objekt besitzt und kann dann belegte Resourcen freigeben.
RMI basiert im wesentlichen auf der Verwendung von Mach-Port zur
Identifikation und Kommunikation und dem Einsatz von
Proxy-Agenten[15] zur Kapselung des
Objektes. Erhält ein Klient Zugriff auf ein Objekt, wird im Rahmen
des dazu notwendigen Protokolls in seinem Adreßraum ein Proxy
für dieses Objekt instanziiert.
3.2.4 Zusammenfassung
Die verschiedenen UNIX-Emulationen unterscheiden sich in ihrer Struktur und in der Art und Weise der Gestaltung der Server. Auf der einen Seite der Singleserver, der quasi einen monolithischen Kern als Nutzerprozß darstellt und auf der anderen Seite die Multiserver-Emulation, die die Funktionalität im Zusammenspiel verschiedener Server erbringt. Dazwischen ordnet sich Spring ein, das die Emulation in einem speziellen Unix-Server unterbringt, der allerdings auf den von Spring bereitgestellten Objekten und Servern aufbaut.
Gemeinsam ist allen drei Systemen, daß es keine speziell für die Emulation übersetzte Anwendungen gibt. Alle stellen einen Mechanismus bereit, der bereits übersetzte Programme mit der Emulation verbindet. Auf Mach ist das der Exception Mechanismus, Spring bedient sich des dynamischen Bindens.
Die Anforderung eines Dienstes erfolgt über die Interprozeßkommunikation, die alle Plattformen bereitstellen. Das beginnt bei einem über Ports realisierten RPC, über den etwas komplexeren RMI-Mechanismus bis hin zum Objektaufruf über Doors in Spring. All diesen Mechanismen ist gemeinsam, daß sie einen Referenzzähler führen, der es einem Server gestattet, das Verschwinden der Klienten eines Objektes zu registrieren.