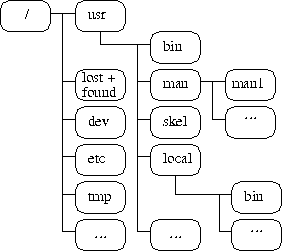
 Ein typischer UNIX-Namensbaum
Ein typischer UNIX-NamensbaumZiel der Arbeit ist es, das UNIX-Prozeßkonzept auf die L3-Konzepte Task und Thread abzubilden. Hierzu wurden in den vorangegangenen Kapiteln verschiedene andere UNIX-Emulationen betrachtet und die Grundkonzepte von L3 vorgestellt.
In diesem Kapitel sollen ausgehend von einer Betrachtung verschiedener
UNIX-Konzepte die bei der Abbildung des Prozeßkonzeptes auftretenden
Probleme untersucht werden. Für diese Probleme werden Lösungsansätze
vorgestellt, aus denen am Ende des Kapitels ein Konzept für die
Prozeß-Verwaltung hervorgeht. 5.1 Ausgangspunkte für den Entwurf und Herangehensweise
UNIX-Emulationen auf
Die Unterschiede sind in der Art und Weise des Entwurfs der Server und der Unterstützung durch den Kern zu finden. Hier gibt es folgende Möglichkeiten:
Der Nachteil ist nicht ganz so offensichtlich. Die einzelnen Komponenten in UNIX sind sehr eng miteinander verwoben. So werden in einer Prozeßtabelle Informationen verwaltet, auf die von nahezu jeder Komponente aus zugegriffen wird. Diese Informationen müssen bei einer Zerlegung in einzelne Module möglichst elegant verwaltet werden. Auf den ersten Blick entsteht dadurch ein höherer Kommunikationsaufwand als bei der Singleserver-Variante. Dieser Punkt darf beim Entwurf der Server nicht außer acht gelassen werden.
Der V-Kern kennt ein spezielles Emulations-Segment im Adreßraum eines Prozesses. Treten außerhalb dieses Segments Ausnahmen(1) auf, werden sie nicht vom Kern behandelt, sondern an die Emulationsbibliothek weitergeleitet. Ausnahmen im Emulations-Segment werden dagegen ganz normal vom Kern behandelt[2].
Andere Systeme bieten allgemeinere Mechanismen zur Lösung dieses Problems an. Mach bietet sogenannte Exception Ports[24], an die im Fehlerfall Nachrichten gesendet werden, Chorus kennt für diesen Fall trap handler, die mittels eines Kerndienstes etabliert werden können. Exception Ports werden im Mach-Singleserver[1] und im Mach-Multiserver[4] genutzt, trap handler finden in der UNIX-Emulation auf Chorus[3] Verwendung.
Chorus bietet zusätzlich die Möglichkeit, die Tasks (Aktoren), die die Server implementieren, in einem privilegierten Modus laufen zu lassen. Die Server laufen im Supervisor Space, was dazu führt, das beim Aktivieren eines Dienstes kein Adreßraumwechsel durchgeführt werden muß. Dem dadurch erzielten Effizienzgewinn steht allerdings gegenüber, daß das Plazieren eines Servers im Supervisor Space faktisch bedeutet, daß der Server zum Kern hinzugebunden wird. Das widerspricht der Philosophie des Mikrokerns und setzt den Kern einem größeren Risiko einer Fehlfunktion aus, da er nun um eine bestimmte Menge Kode größer wird.
Für die L3-UNIX-Emulation wurden folgende Ausgangspunkte festgelegt:
Die UNIX-Emulation muß mit den zur Verfügung gestellten Abstraktionen und Diensten des L3-Kerns auskommen. Hier soll keine spezielle Semantik zur Unterstützung der UNIX-Emulation eingebracht werden. Wie weit dieser Ansatz trägt, wird bei der Implementierung des Konzeptes gezeigt.
Aufgrund der softwaretechnologischen Vorteile einer Modularisierung wird die Multiserver-Variante gewählt. Sicher ließe sich auch in einem Singleserver eine recht gute Modularisierung durchsetzen, aber für den Multiserver sprechen noch andere Gesichtpunkte:
Die API des emulierten UNIX werden durch eine Emulationsbibliothek bereitgestellt, die sich im Adreßraum des Prozesses befindet. Sie nimmt mittels IPC Dienste verschiedener Server in Anspruch, wenn sie den geforderten Dienst nicht allein erbringen kann.
Wie auch in den anderen betrachteten Emulationen sollen die UNIX-Prozesse auf das ihnen am ähnlichsten scheinende Element abgebildet werden. UNIX-Prozesse haben eine eigenen Adreßraum und in der Regel einen einzigen Kontrollfluß. Die Entsprechung hierfür ist in L3 die Task.
Ausgehend von diesen Punkten wurde versucht, eine Struktur für die Emulation zu finden. Da keines der vorhandenen und in den vorangegangenen Kapiteln betrachteten Systeme eine L3-ähnliche Struktur aufweist, kann auch keine Anlehnung an ein vorhandenes System erfolgen. Deshalb wird in diesem Kapitel die folgende Herangehensweise gewählt, um zu einer auf L3 angepaßten Struktur der Emulation zu kommen.
Von Bedeutung sind hier:
UNIX verwaltet verschiedene prozeßspezifische Daten. Ein Teil der Daten kann vom UNIX-Prozeß verändert werden, ohne daß das Auswirkungen auf die Sicherheit oder die Stabilität des Systems hat. Andere Daten dürfen dem UNIX-Prozeß nicht zugänglich gemacht werden, da auf ihnen z. B. die Rechteprüfung u.a.m. aufbaut. Hier wird eine Aufstellung der prozeßspezifischen Daten und eine Einschätzung ihres Einflusses auf die Systemsicherheit vorgenommen. Anhand der Ergebnisse dieses Schrittes werden dann gleichfalls Schlußfolgerungen für die Struktur der UNIX-Emulation gezogen.
Nach Betrachtung der verschiedenen UNIX-Konzepte und -Daten wird hier eine Zusammenfassung der Einzelentscheidungen zu einem Gesamtentwurf vorgenommen, der dann noch einmal dargestellt wird. Dabei werden zwei Unterteilungen vorgenommen:
UNIX stellt an der Kernschnittstelle verschiedene Objekte zur Verfügung. Das sind im wesentlichen folgende, wobei nach benannten und unbenannten Objekten unterschieden wird:
UNIX implementiert zur Verwaltung des Namensraumes eine hierarchische Struktur. Die Struktur wird durch spezielle Dateien (special nodes), die Verzeichnisse, gebildet. Verzeichnisse können neben Dateien auch wieder Verzeichnisse enthalten und bilden dadurch die Hierarchie.
Eine andere Art einer speziellen Datei stellen die Devices dar. Sie bestehen im wesentlichen aus einem Namen, Zugriffsrechten und einer sogenannten Major- und Minornumber. Diese Nummern dienen zur Identifikation der Geräte im Kern, wobei die Majornumber einen Treiber identifiziert, der meist eine ganze Geräteklasse bedient, während die Minornumber eine Unterart dieser Geräteklasse bezeichnet. So repräsentiert beispielsweise die Majornumber 3 in Linux die erste Festplatte, während die Minornumber 0-... die Partitionen auf der Platte identifizieren.
Ein typischer Namensbaum könnte wie in Abbildung [hier] aussehen. Hier ist unter anderem der Zweig /dev hervorzuheben. In diesem Verzeichnis werden im allgemeinen die Devices angelegt. Für diese hierarchische Struktur muß eine entsprechende Abbildung gefunden werden, wobei es die spezielle Semantik der special nodes mit ihrer Major und Minor-Number zu erhalten gilt.
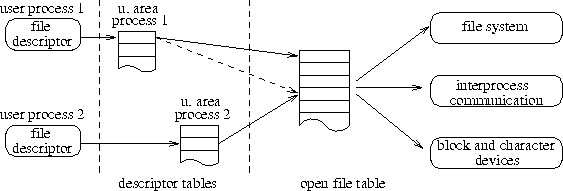
Zugriff auf ein Objekt erhält man durch Vererbung vom Vater-Prozeß, ein open() oder create() bei benannten Objekten oder eine entsprechende Erzeugungsoperation bei unbenannten Objekten (socket(), pipe(), ...). Diese Operationen liefern einen sogenannten Filedeskriptor zurück, über den der Zugriff auf das Objekt erfolgt.
Deskriptoren werden beim Aufruf einer Funktion als Parameter übergeben und gestatten dem UNIX-Kern das Lokalisieren der dazugehörenden Informationen innerhalb verschiedener Kern-Tabellen (Deskriptor-Tabelle, File-Tabelle). Der Deskriptor fungiert dabei im wesentlichen als Index in der Deskriptor-Tabelle, wie in Abbildung [hier] dargestellt wird. Die Deskriptor-Tabelle verweist auf einen Eintrag in der File-Tabelle, in der die eigentlichen Informationen über die Datei aufbewahrt werden. Dazu gehören solche Dinge wie Informationen über den Typ der Datei (File, Socket, Pipe, ...), Filepointer u.a.m. Durch diese Konstruktion wird es möglich, daß zwei Prozesse auf die gleiche Datei schreiben und sich dabei gegenseitig beeinflussen. Der Verweis in der Deskriptortabelle zeigt dann in beiden Prozessen auf den gleichen Eintrag in der File-Tabelle. Diese Situation entsteht durch ein fork() oder durch das Senden eines Filedeskriptors über den ioctl()-Ruf ab SVR4 oder die Socket-Schnittstelle ab 4.2BSD. Hier gilt es, eine adäquate Konstruktion für die Emulation zu finden, die die Semantik der Deskriptoren korrekt widerspiegelt.
 File-Deskriptor
File-Deskriptor
5.2.2 Schlußfolgerungen
Im vorangegangenen Kapitel kristallisierten sich zwei Komplexe heraus, die es im Zusammenhang mit dem Umgang mit UNIX-Objekten zu realisieren gilt:
Entsprechend des Grundgedankens des Multiservers werden für die einzelnen Funktionskomplexe eigene Server vorgesehen. Die Namensauflösung ist ein solcher Komplex, die Bereitstellung von Dateien, Terminals, Sockets u.a.m. sind andere Komplexe. Für jeden dieser Komplexe wird ein spezieller Server geschaffen, der jeweils ein oder mehrere Abstraktionen bereitstellt.
Nun stellt sich folgende Frage: Wie findet der Nutzer den Server, der das von ihm gesuchte Objekt bereitstellt bzw. wie bieten die Server ihre Objekte an?
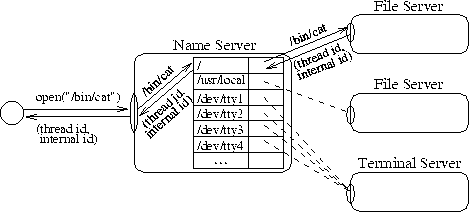
Bei den benannten Objekten geschieht das über eine Namensauflösung. Da es aber mehrere Server geben kann, die benannte Objekte anbieten, muß es einen zentralen Punkt im System geben, der als Ausgangspunkt für die Namensauflösung dienen kann. Deshalb wird hier ein Nameserver eingeführt. Dieser implementiert mit Hilfe anderer Server den hierarchischen UNIX-Namensraum.
 Hierarchischer Namensraum in der UNIX-Emulation
Hierarchischer Namensraum in der UNIX-Emulation
Server, die einen Namensraum implementieren, wenden sich an den zentralen Nameserver und melden bei ihm ihren Namensraum mit Angabe der Position im Wurzel-Namensraum an. Diese Struktur ist in Abbildung [hier] dargestellt.
Ein Klient, der einen Namen auflösen möchte, wendet sich mit einem entsprechenden Auftrag an den Nameserver. Er findet diesen wie alle Server der Emulation, die vertrauenswürdig sein müssen, über eine Anfrage an den Supervisor. Vertrauenswürdige Server müssen einen eindeutigen, festen Namen haben, da sich sonst Sicherheitslücken ergeben. Wäre es z. B. möglich, den verschiedenen Servern einen falschen Authentifizierungsserver(2) unterzuschieben, könnten Prozesse Privilegien erhalten, die ihnen nicht zustehen. Andere Systeme führen hier ähnliche Mechanismen ein, wie z. B. Mach[1] mit dem Nameserver-Port, der jeder Task beim Erzeugen zugeordnet wird. An diesen Port wenden sich die Prozesse mit einem Namen eines Servers und erhalten als Resultat der Anfrage die Id des Servers.
Der Nameserver löst den Namen auf, indem er ihn parsiert und dabei die Dienste der anderen Server in Anspruch nimmt. Um den Kommunikationsaufwand zu verringern, versuchen die Server, die Namen soweit wie möglich aufzulösen und verwenden Cache-Algorithmen zum Puffern von Resultaten.
Auf diese Art werden auch Gerätetreiber eingebunden. Diese befinden sich normalerweise im /dev-Verzeichnis des Wurzelverzeichnisses. Wird nun beispielsweise ein neues Terminal eingerichtet, wendet es sich mit Angabe des Namens, der Geräteklasse und der Identifikatoren der von ihm bereitgestellten Geräte an den Nameserver, der dann Einträge in /dev erzeugt. Stellt der Nameserver beim Auflösen eines Namens fest, daß ein Gerät bezeichnet wird, wird ein spezieller open-Ruf an den entsprechenden Server gesendet, der statt eines Dateinamens die Id des angesprochenen Gerätes enthält. Dadurch weiß der Server, welches der von ihm bereitgestellten Geräte gemeint ist.
Nach Auflösung des Namens und erfolgreichem Öffnen oder Erzeugen des
UNIX-Objektes liefern UNIX-Systemrufe einen File-Deskriptor zurück.
Die Unterscheidung der UNIX-Objekte erfolgt in der
Emulationsbibliothek. Da die Server die Objekte unabhängig von
einander implementieren, muß der Identifikator des Objektes eine
Kombination aus Server-Id und serverinterner Objekt-Id sein. D.h., es
muß eine Abbildung
Für weitere Ausführungen zum Thema Namensauflösung und Architektur der Name- und Fileserver sei auf [25] verwiesen.
Ausgehend von den gegebenen Anforderungen wird ein Deskriptor auf ein Tripel (server id, internal object id, type id) abgebildet. Die Abbildung erfolgt durch eine Tabelle, in der die Tupel verwaltet werden, wobei der Deskriptor als Index dient. Diese Struktur ist in Abbildung [hier] dargestellt. Nach dem Öffnen eines Objektes werden die Id des Servers sowie die Id und der Typ des Objektes in diese Tabelle eingetragen. Nachfolgende Operationen können dann den Server lokalisieren und die Operation entsprechend des Objekttyps durchführen.
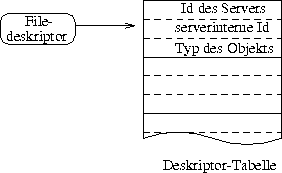 Struktur eines File-Deskriptors in der Emulation
Struktur eines File-Deskriptors in der Emulation
5.2.3 Probleme der Konsistenz
UNIX garantiert für Systemstrukturen unabhängig vom Verhalten der Prozesse einen konsistenten Zustand. Resourcen, die von Prozessen angefordert werden, werden spätestens beim Beenden des Prozesses vom Kern freigegeben. Einen Weg zu finden, diese Konsistenz in die UNIX-Emulation zu übernehmen, ist Ziel der folgenden Betrachtungen.
Der normale Ablauf beim Arbeiten mit einem UNIX-Objekt ist:
Der angesprochene Server reserviert Resourcen, bearbeitet die Aufträge für das Objekt und gibt am Ende die Resourcen wieder frei. Beendet sich ein Prozeß normal (durch Aufruf von exit()), werden von der libc alle noch offenen Dateien geschlossen. Beendet sich ein Prozeß auf nicht normale Art (z.B. durch ein Signal), werden die Dateien vom Kern geschlossen, wobei allerdings von der libc gepufferte Daten verloren gehen. Der Kern kann dies tun, da die Deskriptortabelle in seinem Adreßraum liegt. Dadurch wird garantiert, daß kein Prozeß absichtlich oder unabsichtlich die Konsistenz des Systems beeinflussen kann.
Durch die Verteilung der Information und Funktionalität auf mehrere Server kann es in der UNIX-Emulation in folgenden Situationen zu Problemen kommen:
In beiden Fällen müssen alle Server, deren Dienste der Prozeß zur Zeit in Anspruch nimmt, vom Ende des Prozesses informiert werden.
Die UNIX-Emulation auf Mach[4] und Spring[5] nutzen einen Referenz-Zähler in den Ports bzw. Doors, um festzustellen, wann es keinen Klienten mehr gibt, der auf ein Objekt zugreift. Einen solchen Mechanismus existiert in L3 nicht. Hier gibt es nur die globalen Thread- und Task-Id's.
Es muß also ein Mechanismus gefunden werden, der aufbauend auf den Thread- und Task-Id's eine Überwachung der aktiven Klienten gestattet. Es gibt in L3 zwei Funktionskomplexe, die Informationen über die Existenz von Thread-Id's liefern:
Bei der ersten Variante wird der Supervisor einbezogen und es findet eine Kommunikation statt. Die zweite Variante findet lokal statt, da der entsprechende IPC-Ruf gar nicht erst ausgeführt bzw. abgebrochen wird. Deshalb ist die zweite Variante vorzuziehen.
Bei der Anwendung der IPC-Variante gibt es zwei Varianten, die in Abbildung [hier] dargestellt sind:
Stellt ein Server für jeden Klienten einen Service-Thread bereit, der mittels Receive() auf Aufträge seines Klienten wartet, fällt die Überwachung der Existenz nebenbei ab. Das ist jedoch in UNIX nicht so ohne weiteres möglich, da es jederzeit vorkommen kann, daß zwei Prozesse auf das gleiche Objekt zugreifen(3). Wählt man dann trotzdem Variante (1), wird das sehr aufwendig.
Deshalb wird hier Variante zwei bevorzugt, die bei einer guten Wahl der Abfrageintervalle einen guten Kompromiß zwischen Effizienz und Einfachheit der Lösung bietet.
Die Prozeßverwaltung in UNIX realisiert eine Hierarchie mit dem INIT-Prozeß als Wurzel. Dieses Konzept muß in der Emulation gleichfalls implementiert werden, da UNIX-Programme von der Vater-Sohn-Beziehung regen Gebrauch machen. So werden zum Beispiel Status-Änderungen eines Sohn-Prozesses an den Vater gemeldet, der diese mittels eines wait oder waitpid abfragen kann.
Um hier zu einer Lösung zu kommen, werden in einem ersten Schritt in Abbildung [hier] die verschiedenen Konzepte von UNIX und L3 gegenübergestellt.
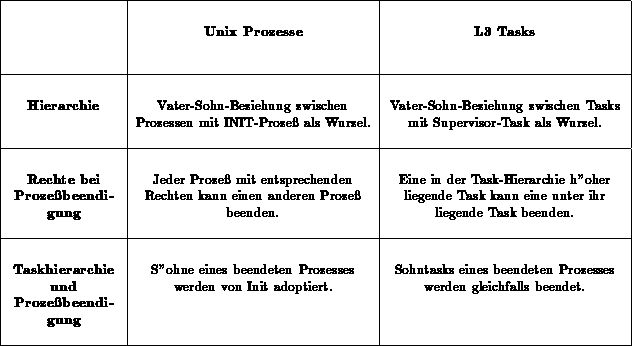 Gegenüberstellung der Verwaltungskonzepte von L3 und UNIX
Gegenüberstellung der Verwaltungskonzepte von L3 und UNIX
L3 realisiert gleichfalls eine Vater-Sohn-Beziehung zwischen den Tasks. Diese kann aber nicht zur Implementierung der UNIX-Prozeß-Hierarchie benutzt werden, da es dann Probleme beim Beenden eines Prozesses gibt. Auf der einen Seite könnte es passieren, daß ein Prozeß seinen Vater-Prozeß beenden möchte, wozu er theoretisch das Recht haben kann. Aufgrund der L3-Taskhierarchie wäre das aber nicht möglich. Auf der anderen Seite würde eine Beendigung eines Prozesses auch die Beendigung seiner Sohn-Prozesse zur Folge haben. Auch das ist nicht vertretbar.
Deshalb wird eine spezielle Task eingeführt, die als Vater aller
UNIX-Tasks fungiert, die eigentliche UNIX-Prozeß-Hierarchie
verwaltet und diese über IPC zur Verfügung stellt. Langfristig ist
hier eine Anpassung des Supervisors denkbar, der dann eine
Taskverwaltung implementiert, die näher an der UNIX-Semantik liegt. 5.4 Authentifizierung der Prozesse
Systemrufe in UNIX sind in der Regel an Rechte gebunden. So werden z. B. für die Dateien rudimentäre Zugriffs-Steuer-Listen (Access Control Lists) geführt, die entsprechend den gesetzten Rechten nur dem Nutzer, der Gruppe oder allen das Lesen, Schreiben oder Ausführen gestatten. Ein anderes Beispiel ist das Senden von Signalen. Hier darf nur Root an beliebige Prozesse Signale senden, z. B. um vor dem Herunterfahren eines Systems alle Prozesse zu beenden. Sonst ist der Anwender auf Prozesse beschränkt, die ihm selbst gehören.
 Die verschiedenen Id's, die jedem Prozeß zugeordnet werden
Die verschiedenen Id's, die jedem Prozeß zugeordnet werden
Die Rechte werden in UNIX an die User Id (UID) bzw. die Group Id (GID) gebunden. Jedem Nutzer ist genau eine UID und eine GID zugeordnet, ihm können aber auch noch zusätzliche Gruppen zugeordnet sein. Diese werden supplementary groups genannt. Ein Überblick über die jedem Prozeß zugeordneten Id's ist in Abbildung [hier] zu finden.
Da es einem Nutzer auch möglich sein muß, privilegierte Operationen auszuführen, z. B. eine Datei in die Druckerqueue einzufügen, auf die er normalerweise keinen Zugriff hat, gibt es die Möglichkeit, die UID temporär zu wechseln. Für diesen Zweck wurde eine zweite UID eingeführt, die sogenannte effective user id. Programme, die erweiterte Rechte benötigen, gehören in der Regel einem mit entsprechenden Rechten ausgestatteten Nutzer und haben ein sogenanntes setuid-Bit gesetzt. Führt ein Anwender dieses Programm aus, wird seine effektive UID auf die Id des Eigentümers gesetzt und er kann die entsprechenden Operationen ausführen. Damit das Programm während seiner Laufzeit aber auch Rechte abgeben und wieder erlangen kann, wurde in POSIX die sogenannte saved UID eingeführt[26].
Auf den Id's beruht das Rechte-Schema von UNIX. Es darf also nicht
möglich sein, diese Id's zu fälschen. Es muß eine Möglichkeit gefunden
werden, die eine eindeutige, nicht fälschbare Ermittlung der UID
gestattet. Dazu werden in einem ersten Schritt die zur Verfügung
stehenden L3-Konzepte betrachtet und ihre Anwendungsmöglichkeiten
geschildert. Dann wird eine Bewertung vorgenommen und eine Möglichkeit
ausgewählt. 5.4.1 Kernkonzepte als Grundlage der Authentifizierung
Wie in Kapitel [hier] dargestellt wurde, gibt es in L3 vier wesentliche Konzepte:
Der External Pager-Mechanismus könnte zur Realisierung eines verteilten Zustandes durch shared memory verwendet werden. Ein Beispiel wird im folgenden vorgestellt.
Da die Anforderung eines Dienstes von einem Server durch Interprozeßkommunikation erfolgt, kommt nur ihre Integritätseigenschaft in Frage. Diese hat zwei Aspekte. Sieht man vom Clans & Chief Konzept ab, kann man sich auf
stützen. Für beide werden im weiteren Anwendungsmöglichkeiten vorgestellt.
5.4.2 Implementierung eines verteilten Zustandes durch einen externen
Pager
In [27] wird die Verwendung eines blackboard servers beschrieben, um den verteilten Systemzustand zu verwalten, während in [1] die Verwendung von shared memory zur Erhöhung der Performance von Systemrufe wie getpid() geschildert wird. Beide beruhen auf der Verwendung des External Pager-Prinzips.
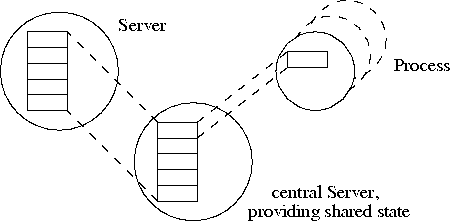 Implementierung eines verteilten Zustandes mit Hilfe eines
externen Pagers
Implementierung eines verteilten Zustandes mit Hilfe eines
externen Pagers
Diese Idee ließe sich in der UNIX-Emulation auf L3 gleichfalls einsetzen. Ein zentraler Server verwaltet die UNIX-Id's der Prozesse und stellt sie anderen Servern und den Prozessen read only zur Verfügung. Diese Struktur könnte wie in Abbildung [hier] aussehen.
Die Server mappen die gesamte Tabelle, die Prozesse nur ihren Eintrag. Das kann vom Server transparent implementiert werden, indem bei einer Anforderung eines Prozesses die ihm zugeordnete Seite zurückgegeben wird, während die Server eine Seite entsprechend ihres Zugriffes zurückbekommen.
Nachteil dabei ist, daß ein Tabelleneintrag immer auf einer Seitengrenze beginnen muß, also für jeden Eintrag eine Seite benötigt wird. Hinzu kommt, daß bei einer Iteration über die Tabelle im ungünstigsten Fall bei jedem Zugriff ein Seitenfehler entsteht. Will man dies verhindern, muß man entweder den Prozessen gleichfalls Zugriff auf die gesamte Tabelle gewähren oder für die entsprechenden Systemrufe einen anderen Mechanismus implementieren, womit die Allgemeinheit der Lösung nicht mehr gegeben ist.
Ein anderer Nachteil ist die Notwendigkeit von Sperr-Mechanismen zum
Schutz der Datenstrukturen vor Inkonsistenzen. Diese Inkonsistenzen
können zwar nur beim Auslesen von Daten entstehen, da die
Datenbereiche nur read only gemappt werden, aber die Folgen
können ähnlich sein.
5.4.3 Identifikation durch Nachrichteninhalt - Capabilities (Amöba)
Tanenbaum beschreibt in [28] eine Möglichkeit, Prozessen Rechte auf Objekte einzuräumen. Er führt eine Datenstruktur ein, die den Objekttyp, die Rechte an diesem Objekt und einen Verweis auf das Objekt selbst enthält. Diese Struktur wird Capability genannt. Sie wird dem Prozeß zugeordnet und oft in einer Tabelle oder Liste verwaltet. Prozesse beziehen sich dann mit Hilfe der Position auf das Capability.
Da diese Capabilities Rechte enthalten, ist es naheliegend, daß sie vor einem unberechtigten Zugriff des Nutzers geschützt werden müssen. Hier führt Tanenbaum neben Hardwareunterstützung (tagged memory) und Plazieren der Tabelle im Kern-Adreßraum kryptographische Methoden ein.
Das Capability wird mit einer großen Zufallszahl geschützt, die nicht mit vertretbarem Aufwand zu erraten ist. Der Eigentümer hat zunächst alle Rechte an einem von ihm erzeugten Objekt. Er kann diese Rechte einschränken. Dazu schickt er das Capability mit einer neuen Rechte-Maske an den Server, der mit Hilfe einer Einweg-Funktion ein überprüfbares, eingeschränktes Capability generiert. Dieses kann dann an andere Prozesse weitergegeben werden, die nur Operationen ausführen können, die von diesem neuen Capability zugelassen werden.
 Der Aufbau von Capabilities in Amöba
Der Aufbau von Capabilities in Amöba
Amöba [29] nutzt diese Art, um Rechte auf Objekte zu vergeben. Der Aufbau eines Capability in Amöba ist in Abbildung [hier] dargestellt.
Würde man einem Prozeß nach dem login ein Capability übergeben, das seine Id beschreibt, kann er sich bei den verschiedenen Servern damit ausweisen. Diese können die Identität beim ausstellenden Server prüfen lassen und dann ein Capability für das gewünschte Objekt zurückgeben. Diese müßte dann bei jeder gewünschten Operation präsentiert werden, um die Berechtigung des Zugriffs nachweisen zu können.
Der Vorteil der Capabilities liegt zum einen in der Flexibilität der Verwendung und zum anderen in der guten Eignung für verteilte Systeme. Hat ein Klient Zugriff auf ein Objekt erhalten, kann er dieses Zugriffsrecht in Form des Capabilities an jede andere Task weitergeben. Ein Server kann den Zugriff auf ein Objekt ohne Ansehen des Klienten gestatten, was einen flexiblen Einsatz ermöglicht.
Der Nachteil liegt im höheren Kommunikationsaufwand, der durch die
längere Nachricht entsteht.
5.4.4 Identifikation auf Grundlage des Absenders
Ein anderer Ansatz ist die Identifikation des Prozesses auf Grundlage
einer L3-Architektureigenschaft. Es müßte eine Abbildung der Art
Eine solche Eigenschaft ist der Absender der Nachricht, mit der sich
ein Klient an einen Server wendet. Thread- und Task-Id's in L3 sind
eindeutig in Zeit und Raum. Aufbauend auf dieser Eigenschaft läßt sich
eine Abbildung
Eingesetzt werden kann diese Abbildung in zwei Varianten, zum einen in
Verbindung mit dem Clans & Chiefs-Konzept, und zum anderen
durch Schaffung eines vertrauenswürdigen Server, der die
Authentifizierung auf Anfrage vornimmt. Anwendung des Clans & Chiefs-Konzepts
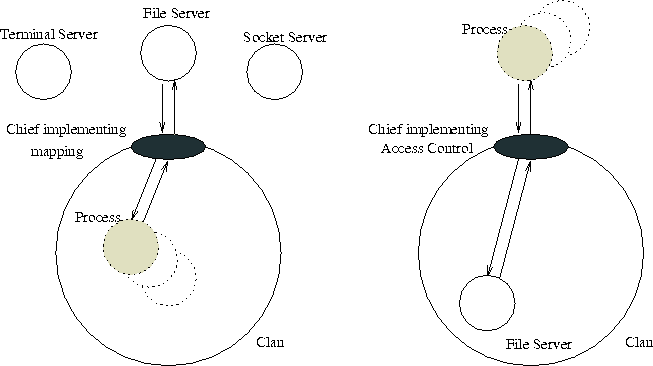 Anwendung des Clans & Chief Konzept
Anwendung des Clans & Chief Konzept
Mit Hilfe des Clans & Chiefs-Konzepts kann eine transparente Abbildung der Thread-Id auf die uid bzw. eine transparente Realisierung von Zugriffs-Steuer-Listen (Access Control Lists) implementiert werden. Welche Variante realisiert wird, hängt von der Art und Weise der Erzeugung des Clans und der Implementierung des Chiefs ab. Abbildung [hier] stellt beide Varianten gegenüber.
Auf der einen Seite bilden alle UNIX-Prozesse einen Clan. Die Server befinden sich außerhalb des Clans. Fordert ein Klient einen Dienst eines Servers, verläßt diese Botschaft den Clan und wird damit über den Chief umgeleitet. Dieser nimmt anhand der Thread-Id des Absenders eine Identifizierung des Klienten vor und trägt dessen Id's in die Nachricht ein. Dann wird die Nachricht an den eigentlichen Adressaten, einen Server, weitergeleitet. Vorausgesetzt, der Chief ist vertrauenswürdig und liefert eine korrekte Abbildung, haben die Server alle notwendigen Informationen, um die Einhaltung der Rechte zu gewährleisten. Sie implementieren dann auf Grundlage der mitgelieferten Id's ihre eigene Access Control-Strategie.
Der andere Ansatz kapselt die einzelnen Server jeweils in einem separaten Clan. Dienstanforderungen eines Klienten passieren dann die Clan-Grenze von außen nach innen, werden also über den Chief des Server-Clans umgeleitet. Dieser kann dann anhand der Thread-Id des Absenders eine allgemeine oder auf den Server angepaßte Access Control-Strategie implementieren. Diese ist für den Server transparent. Es werden nur Anforderungen an ihn weitergeleitet, zu denen der Client auch das Recht hat. Der Server braucht dann keine Zugriffskontrolle mehr implementieren.
Die Überprüfung von Rechten anhand der Id des Prozesses ist allerdings nur bei Initialaktionen notwendig. Hiermit sind Aktionen gemeint, die dem Klienten Zugriff auf ein Objekt verschaffen, wie z. B. open(). Kann ein Klient ein open() ausführen, kann er auch alle folgenden Operationen auf dem Objekt ausführen. Eine nochmalige Rechteprüfung im Sinne einer Prüfung der (UNIX-)Id des Prozesses ist nicht mehr notwendig. Hier reicht eine Prüfung, ob der Klient immer noch derjenige ist, dem man die Rechte gewährt hat. Das kann jederzeit anhand der Thread-Id des Absenders geschehen.
Die Verwendung von Clans würde aber bedeuten, daß die Prüfung bzw. zumindestens die Umleitung über den Chief jedesmal durchgeführt werden würde. Neben diesem höheren Kommunikationsaufwand kommt auch noch eine höhere Nachrichtenlänge hinzu, da in den Nachrichten Platz für das Eintragen der Id's reserviert werden muß.
Der Vorteil dieser Lösung liegt in ihrer Transparenz für die
Klienten. Entweder der Server kann sich auf die Korrektheit der in der
Nachricht enthaltenen Id's verlassen, oder er erhält von vornherein
nur Aufträge, zu denen der Klient auch das Recht hat.
Schaffung eines zentralen Authentifizierungsservers
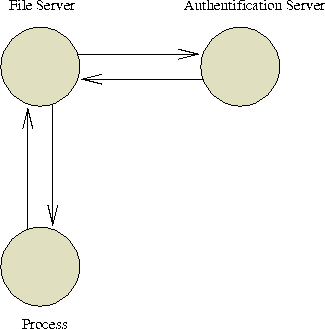 Einrichtung eines zentralen Authentifizierungsservers
Einrichtung eines zentralen Authentifizierungsservers
Ein mehr expliziter Ansatz ist die Einrichtung eines zentralen Authentifizierungsservers. Diese Struktur ist in Abbildung [hier] dargestellt. Erhält ein Server eine Anforderung eines Klienten, wendet er sich mit dessen Thread-Id an den Authentifizierungsserver. Dieser bildet die Thread-Id auf die Id's des UNIX-Prozesses ab und liefert diese Informationen zurück. Der anfragende Server kann mit Hilfe der gelieferten Informationen über die Zulässigkeit der Anforderung des Klienten befinden und diese evtl. ablehnen.
Diese Abbildung ist von außen nicht beeinflußbar, da der Kern die Autonomie der Task garantiert. Befindet sich zwischen anfragendem und Authentifizierungsserver kein Chief, kann die Kommunikation auch nicht gestört werden. Dieser Aspekt muß bei der Einrichtung der Taskhierarchie berücksichtigt werden.
Für die Notwendigkeit der Ermittlung der Id's gelten sinngemäß die im vorangegangenen Kapitel gemachten Ausführungen. Im Gegensatz zum Clan & Chief-Konzept entscheidet hier allerdings der Server, wann er sich Informationen über einen Klienten beschaffen muß. Es ist ihm freigestellt, Pufferalgorithmen zu implementieren, die den Kommunikationsaufwand verringern. Hinzu kommt, daß diese Variante keinen Einfluß auf den Aufbau der Nachrichten hat.
Bei der Verwendung von Puifferalgorithmen muß allerdings die Möglichkeit
berücksichtigt werden, daß ein Prozeß seine Id temporär ändern kann
und damit Rechte hinzubekommt oder abgibt. Wird diese Variante
gewählt, sind hierzu weitere Untersuchungen notwendig.
5.4.5 Bewertung der Lösungen und Auswahl einer Lösung
Es stehen jetzt drei Varianten zur Diskussion, die alle verwendbar und auch umsetzbar sind. Jede hat Vor- und Nachteile, die in Abbildung [hier] noch einmal in tabellarischer Form gegenübergestellt werden.
 Vor- und Nachteile der verschiedenen Authentifizierungskonzepte
Vor- und Nachteile der verschiedenen Authentifizierungskonzepte
Ausgewählt wurde die Variante drei, die Bereitstellung eines speziellen Authentifizierungsservers. Dieser bringt genau den Umfang an Funktionalität, der für die Realisierung der UNIX-Rechte notwendig ist. In Verbindung mit der Realisierung von Pufferalgorithmen in den anfragenden Servern läßt sich auch der Kommunikationsaufwand zum Ermitteln der Id's auf ein Minimum reduzieren.
Die anderen Lösungen bieten auf Kosten der Effizienz
Vorteile wie Flexibilität und Transparenz. Diese lassen sich bei
korrekter Implementation des Authentifizierungsservers und der
Schnittstelle dazu aber gleichfalls erreichen. Das einzige, was sich
nicht so ohne weiteres realisieren läßt, ist die Weitergabe von
Rechten ohne das Hinzuziehen des Servers, was bei Capabilities in
Amöba möglich ist.
5.4.6 Probleme dieser Lösung
Betrachtet man die ausgewählte Lösung, stellt man schnell fest, daß sie ein Problem hat. Sie erreicht ihre Einfachheit und Effizienz durch eine Abbildung der Thread-Id auf die UNIX-Id des Prozesses in Verbindung mit Pufferalgorithmen, um den Kommunikationsaufwand zu minimieren. Meldet sich ein Klient das erste mal beim Server, fragt dieser beim Authentifizierungsserver nach, um sich die Id's des Prozesses geben zu lassen. Diese werden für spätere Forderungen des Klienten gepuffert.
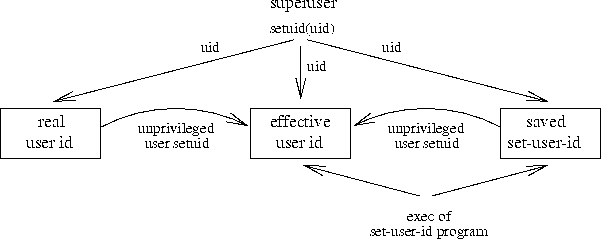 Die Möglichkeiten eines Prozesses, seine Id zu ändern
Die Möglichkeiten eines Prozesses, seine Id zu ändern
Der Klient kann aber inzwischen durch Ausführen eines execve() oder setuid() seine Id und damit auch seine Rechte geändert haben. Die verschiedenen Möglichkeiten der Rechteänderung sind in Abbildung [hier] dargestellt. Greift der Server nun auf die zwischengespeicherten Daten zu, gewährt er dem Klienten unter Umständen zuviel Rechte oder verweigert ihm welche. Das muß verhindert werden.
Bei der Lösung dieses Problems kann man von zwei Punkten ausgehen:
Zur Lösung dieses Problems gibt es prinzipiell zwei Ansätze:
Der erste Ansatz würde eine Aktivität des Autentifizierungsservers in Form der Verwaltung der involvierten Server oder die Implementierung eines Broadcastmechanismus erfordern. Daher ist prinzipiell der zweite Ansatz vorzuziehen. Dazu muß allerdings eine Möglichkeit gefunden werden, die den Servern gestattet, eine Änderung zu registrieren.
Wie in Kapitel [hier] ausgeführt, kommen dabei zwei Eigenschaften in Frage. Der Inhalt der Nachricht kann dabei nicht verwendet werden, da er vom Klienten bereitgestellt wird. Ein Prozeß, der eine Täuschung versucht, wird ein mit Hilfe des Nachrichteninhaltes implementiertes Protokoll nicht befolgen. Bleibt also nur der Absender, der eindeutig in Zeit und Raum ist. Nun stellt sich die Frage, wie diese Eindeutigkeit realisiert wird und ob sie hier einsetzbar ist.
 Der Aufbau von Thread-Id's in L3
Der Aufbau von Thread-Id's in L3
Der Aufbau der Thread-Id ist in Abbildung [hier] dargestellt. Interessant sind hier:
Die Versionsnummer wird bei zwei Anlässen verändert:
Damit ist eine Möglichkeit gefunden. Benennt man den UNIX-Thread (den ersten Thread in der UNIX-Task) beim Ändern seiner Rechte um, können die Server die Änderung bemerken. Zugleich erkennen sie ihren früheren Klienten immer noch, da sich dessen Threadnummer nicht verändert hat. Die Server könnten dann nach folgendem Schema verfahren:
receive message;
if (client known)
{
get cache information
}
else
{
if (client's thread number known)
{
get information from authentification server
update cache entry
}
else
{
get information from authentification server
create new cache entry
}
}In den vorangegangenen Ausführungen wurde primär die Durchsetzung umfangreicherer Rechte betrachtet. Dadurch wurden zwei andere Aspekte außer Acht gelassen:
Beide Probleme resultieren aus der Implementierung des execve()-Systemrufs als Funktion der Emulationsbibliothek. Dadurch ist eine Manipulation bzw. Nachbildung der Funktion durch den Prozeß möglich.
Die Verringerung der Rechte ist für die Sicherheit des Systems nicht von Bedeutung. Ein Programm, daß sich beim Ausführen eines setuid-Programms nicht an das Protokoll hält, gewährt diesem maximal die Rechte, die ihm selbst zustehen. Den Schaden, den es damit anrichten kann, hätte das ausführende Programm selbst anrichten können. Deshalb muß die Verringerung nicht unbedingt durchgesetzt werden.
Wesentlich interessanter ist der zweite Punkt. Da ein UNIX-Prozeß
durch eine L3-Task emuliert wird, hat er vollen Zugriff auf seinen
Adreßraum. Manipuliert er ihn in der Art, daß nach Ausführung eines
setuid-Programms mit neuen Rechten ein vom usprünglichen Programm
im Adreßraum installiertes Kode-Stück ausgeführt wird, kann das zu
Sicherheitsproblemen führen. Wie mit diesem Problem umgegangen wird,
wird im Kapitel [hier] beschrieben.
5.4.7 Verallgemeinerung des Problems
UNIX verwaltet nicht nur Id's pro Prozeß. In der entsprechenden Verwaltungsstruktur (u. Area in BSD) werden noch andere, wichtige Informationen wie die Prozeß-Id, die Prozeßhierarchie, die Prozeßgruppen u.a.m. verwaltet. Das hier am Beispiel der Id's des Prozesses beschriebene Modell läßt sich auch für die Verwaltung der anderen Informationen verwenden.
Die drei Hauptgruppen der zu verwaltenden Informationen sind dabei:
Die Verwaltung dieser Informationen ist mit dem vorgestellten Modell möglich und wird von einem zentralen Prozeßserver(3) übernommen. Dieser dient dann als Auskunftsstelle für prozeßspezifische Informationen.
Signale spielen im Prozeßkonzept von UNIX eine bedeutende Rolle. Sie
stellen Softwareunterbrechungen dar, die zum Anzeigen asynchroner
Ereignisse dienen. So werden zum Beispiel Signale gesendet, wenn ein
Nutzer auf der Tastatur die Interrupt-Taste drückt oder sich der
Zustand eines Sohn-Prozesses ändert. Signale existieren seit den
ersten UNIX-Versionen, waren damals aber noch unzuverlässig. Signale
konnten verloren gehen und es war schwer, Signale zu unterdrücken,
während kritische Kode-Teile ausgeführt wurden. Deshalb führten die
beiden Hauptlinien (BSD, SV) ein neues Signalmodell ein. Die in 4.3BSD
und SVR3 eingeführten Modelle wahren jedoch inkompatibel zueinander.
POSIX definiert das BSD-Modell als Standard. Die POSIX-Definition soll
den folgenden Ausführungen zugrunde liegen. 5.5.1 Signale
BSD-Signale und damit auch POSIX-Signale wurden nach dem Modell der Hardware-Interrupts entworfen[30]. Sie haben folgende Eigenschaften:
Signale können vom Standpunkt des Nutzers zu jedem beliebigen Zeitpunkt auftreten.
Jedem Signal ist eine feste Bedeutung zugeordnet. Diese Bedeutung ist in den Dokumentationen zum System zu finden. Eine bestimmte Menge von Signalen muß von jedem POSIX-konformen System unterstützt werden. Sie sind in [26] 3.3 beschrieben.
Prozesse können sich mittels des kill()-Rufes gegenseitig Signale senden. Zusätzlich werden vom Kern Signale generiert, wenn die Hardware eine Ausnahme signalisiert (Zugriff auf ein ungültiges Segment, Division durch Null, Nicht aligned-ter Speicherzugriff u.a.m.) oder wenn ein kerninternes Ereignis eintritt (Schreiben in eine Pipe, zu der es keine Leser mehr gibt, Drücken der Stop-Taste am Terminal u.a.m.)
Nicht jeder Prozeß kann an jeden ein Signal senden. Das Sende-Recht wird an der uid, euid und suid festgemacht.
Jedem Signal ist eine Standardreaktion zugeordnet. Diese kann sein:
Die Zuordnung ist in [26] 3.3.1.3 beschrieben. Diese Standardreaktion kann durch eine programmspezifische Reaktion ersetzt werden, indem dem Signal ein Signalhandler zugeordnet wird. Dieser Signalhandler wird beim Auftreten eines Signals aktiviert. Der aktuelle Zustand des Prozesses wird gesichert, der Kontext für den Signalhandler aufgebaut und der Handler aufgerufen. Kehrt er zurück, wird das Programm normal fortgesetzt.
Ein Signal kann auch blockiert werden. Es bleibt dann in den Verwaltungsstrukturen vermerkt bis es entweder auf Ignoriert gesetzt und damit verworfen oder deblockiert und damit zugestellt wird.
In diesem Schema gibt es zwei Ausnahmen. Die Signale SIGKILL(1) und SIGSTOP(2) dürfen nicht ignoriert oder von einem nutzerdefinierten Signalhandler behandelt werden(3).
In UNIX werden in Hinsicht auf Signale zwei Arten von Systemrufen unterschieden, unterbrechbare und nicht unterbrechbare. Dieser Aspekt spielt nur bei Systemrufen eine Rolle, die bei ihrer Ausführung auf das Eintreten eines Ereignisses warten müssen (Freiwerden eines Puffers, Eintreffen eines Zeichens vom Terminal, ...). Ob ein Systemruf beim Auftreten eines Signals unterbrochen wird oder nicht, wird an der Art des Ereignisses festgemacht, auf das der Prozeß wartet. Ist zu erwarten, daß das Ereignis in relativ kurzer Zeit eintritt (Freiwerden eines Puffers), wird nicht unterbrochen. Ist nicht vorhersehbar, wann das Ereignis eintritt, wird der Systemruf unterbrochen und der Signalhandler aktiviert. Dann wird unter Umständen versucht, den Systemruf wieder aufzusetzen. Ist das nicht möglich, wird ein Fehler zurückgeliefert.
In den vorangegangenen Ausführungen kristallisierten sich vier wesentliche Punkte heraus:
Betrachtet man 2. unter der Berücksichtigung der Autonomie der Task, kann man schlußfolgern: Signale müssen auf IPC abgebildet werden, da IPC die einzige Möglichkeit ist, eine Task von außen zu beeinflussen. Nun ist die IPC in L3 allerdings synchron, d. h. der Empfänger muß bereit sein, die Nachricht zu empfangen. Hier ist schnell zu erkennen, daß eine Task mit einem einzelnen Thread nicht in der Lage ist, die Zustellung zu gewährleisten. Die Abfrage auf das Vorhandensein von Signalen könnte nur in der C-Bibliothek erfolgen, da man vom Nutzer nicht erwarten kann, daß er sich um die Zustellung von Signalen kümmert. Führt das Programm nun aber eine längere Berechnung durch, kann während dieser Zeit kein Signal zugestellt werden. Deshalb muß ein pro Prozeß spezieller Signal-Thread eingeführt werden, der bereit ist, Signale zu empfangen.
Nach dem Empfang des Signals muß allerdings unter Umständen ein nutzerdefinierter Signalhandler aufgerufen werden. Dadurch entsteht ein neues Problem: Ein UNIX-Prozeß (Single-Threaded) kann sich darauf verlassen, daß es während seiner Ausführung keine Wettkampfbedingungen gibt, da er der einzige Kontrollfluß im Prozeß ist. D. h., daß:
Geht man davon aus, daß der Signalhandler selbst wieder Systemrufe ausführt(4), die ihrerseits wieder unterbrochen werden können, wird man der zweiten Variante den Vorzug geben. Sie gestattet beliebig tief geschachtelte Signalhandler, während der Signal-Thread beim Ausführen des Signalhandlers keine weiteren Signale akzeptieren könnte. Um dies zu erreichen, müßte bei Aktivierung eines Signalhandlers ein neuer Signal-Thread erzeugt werden. Das würde die Komplexität der Signalbehandlung aber unnötig vervielfachen.
Betrachtet man Punkt drei und vier, kommt man zu der Erkenntnis, daß ein externer Prozeß in die Signalzustellung einbezogen werden muß. Dieser Prozeß müßte für die Kontrolle der Rechte beim Senden eines Signals und für die unbedingte Zustellung der Signale SIGKILL und SIGSTOP sorgen.
Zusammenfassend läßt sich sagen, es sind folgende Entscheidungen gefallen:
Eine nähere Betrachtung des Umgangs mit den Signalen SIGKILL und SIGSTOP erfolgt in Kapitel [hier].
In den vorangegangenen Kapiteln wurden verschiedene Aufgaben für Server definiert. Neben solchen elementaren Servern, wie Terminalserver, Fileserver und Nameserver wurden drei Server beschrieben, die:
Die drei Komplexe sind so eng miteinander verbunden, daß es sich
anbietet, sie in einem Server zusammenzufassen. Dieser soll im
weiteren Prozeßserver genannt werden.
5.6.2 Der UNIX-Prozeß
Für den UNIX-Prozeß fiel nur eine wichtige Entscheidung: Er ist nicht Single-Threaded, wie ein normaler UNIX-Prozeß, sondern geteilt in:
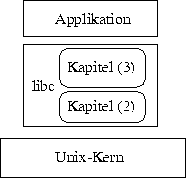 Die Schichten eines UNIX-Programms
Die Schichten eines UNIX-Programms
Über die Art und Weise der Zusammenarbeit der Emulationsbibliothek und der Anwendung wurden bisher keine Ausführungen gemacht. Dafür sollen im folgenden die Grundlagen gelegt werden.
Eine UNIX-Anwendung läßt sich, wie in Abbildung [hier] dargestellt, logisch in drei Schichten gliedern. Diese Schichten haben die folgende Funktion:
Der Kapitel (2)-Teil der C-Bibliothek kapselt das Application Binary Interface (ABI) des UNIX-Kerns. Die Kapitel (2)-Funktionen bereiten die Parameter entsprechend der Schnittstelle auf, bringen sie an die vereinbarten Übergabestellen und betreten dann den Kern.
Die Kapitel (3)-Funktionen der C-Bibliothek stellen aufbauend auf den Kapitel (2)-Funktionen höhere Abstraktionen zur Verfügung. Hier werden z. B. aus Filedeskriptoren Streams, die Daten puffern und komfortable Funktionen wie fprintf u.a.m. zur Verfügung stellen.
Dieser Teil enthält den eigentlichen Programmkode, der das Programm ausmacht. Er baut auf Funktionen der C-Bibliothek auf.
Die UNIX-Emulation stellt die Funktionalität des Kerns bereit. Daraus folgt, daß die Emulation die Funktionalität der Kapitel (2)-Systemrufe bereitstellen muß. Dafür gibt es zwei verschiedene Ansätze, der Entwurf einer speziellen C-Bibliothek und das Abfangen der Kerneintritte der normalen C-Bibliothek. Beide Varianten sind in Abbildung [hier] dargestellt.
Eine spezielle Emulationsbibliothek erbringt die Dienste direkt unter Zuhilfenahme der Server. Das hat den Vorteil, daß ein Systemruf ein lokaler Prozeduraufruf ist, was Effizienzvorteile bringt. Ein Vertreter dieser Kategorie ist Spring[5]. Hier wird die Emulationsbibliothek dynamisch zum Programm hinzugebunden. Bei anderen Systemen werden die Programme speziell für die Emulation zusammengebunden.
Die zweite Variante greift nicht in die Struktur des Programms ein, sondern setzt an der Stelle an, an der die C-Bibliothek den Kern betreten will. Dieser Kerneintritt wird abgefangen, die Parameter entsprechend des ABI analysiert und an die zugehörige Funktion der Emulationsbibliothek übergeben. Diese erbringt in Zusammenarbeit mit den Servern den geforderten Dienst. Anschließend wird zur Aufrufstelle im Programm zurückgekehrt. Die Mechanismen zum Abfangen der Systemrufe beruhen alle auf einem ähnlichen Prinzip. Die C-Bibliothek verwendet einen speziellen Befehl, um in den Kern zu gelangen. Dieser verursacht in den meisten Systemen, auf denen UNIX emuliert wird, eine Ausnahme aufgrund einer illegalen Anweisung. Dieser wird dann von der Emulation abgefangen. In Mach geschieht das über den Exception-Mechanismus [1][4], in V wird eine Ausnahme außerhalb des Emulationssegments an die Emulationsbibliothek weitergeleitet[2] und Chorus definiert spezielle Exceptionhandler[3].
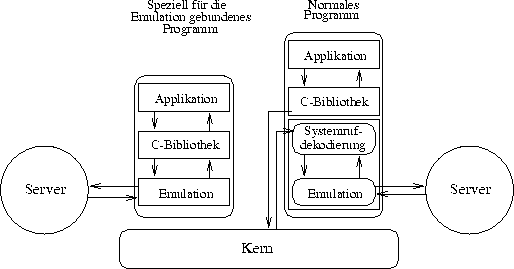 Verschiedene Arten der Anbindung der Emulation
Verschiedene Arten der Anbindung der Emulation
Für die UNIX-Emulation wurde für den Anfang der Entwicklung aus den folgenden Gründen das Abfangen der Systemrufe als Eintrittspunkt in die Emulation gewählt:
Die genaue Realisierung des Abfangens der Systemrufe wird in Kapitel [hier] beschrieben.
Ein anderer Aspekt ist die Abbildung eines ausführbaren Programms im Speicher. Ein Programm besteht unter UNIX aus vier Bestandteilen, dem Kode-Segment, dem Daten-Segment, dem BSS-Segment(2) und dem Stack-Segment. Während des Programmlaufs wächst das BSS-Segment entsprechend den Anforderungen des Prozesses in Richtung Stack, der dem Segment von oben entgegenkommt.
Diese vier Bestandteile lassen sich im Standarddatenraum einer Task unterbringen. Sollte sich im Laufe der Entwicklung zeigen, daß es Programme gibt, denen 32 Megabyte für Programmkode und Daten nicht ausreichen, muß ein spezieller Halde-Datenraum eingeführt werden. Dieser unterliegt dann nicht den Beschränkungen des Standarddatenraums und kann damit beliebig (im Rahmen des 3,5 Gigabyte Adreßraums) wachsen. Eine Alternative ist die Anpassung des Supervisors, der dann den Standarddatenraum nicht mit 32 Megabyte, sondern einer flexibel festlegbaren Größe mappt.
Aus den getroffenen Entscheidungen ergibt sich für den UNIX-Prozeß die in Abbildung [hier] dargestellte Struktur. Der UNIX-Thread arbeitet das UNIX-Programm ab und betritt dabei über den Umweg des Systemrufabfangens die Emulationsbibliothek. Der Signalthread wartet während seiner gesamten Existenz auf das Eintreffen von Signalen und stellt diese dem UNIX-Thread zu. Er bewegt sich also die ganze Zeit innerhalb der Emulationsbibliothek. Die Zustellung der Signale, die Realisierung unterbrechbarer Systemrufe, wird in Kapitel [hier] beschrieben.
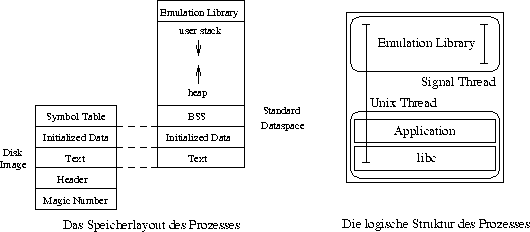 Die Struktur des UNIX-Prozesses
Die Struktur des UNIX-Prozesses
5.6.3 Die Struktur des Systems
Ausgehend von den bis jetzt getroffenen Entscheidungen zeichnet sich die in Abbildung [hier] dargestellte Struktur ab:
UNIX verwaltet in internen Tabellen verschiedene Daten pro Prozeß. Die
in der UNIX-Emulation verwendeten Daten sollen im folgenden kurz
aufgelistet und ihre Relevanz für die Sicherheit des Systems
betrachtet werden. 5.7.1 Übersicht über die verwendeten Daten
In [31] und [30] werden die Datenstrukturen der Prozeßverwaltung zweier UNIX-Varianten beschrieben. POSIX [26] äußert sich nur zu Daten, die an der Schnittstelle des Systems sichtbar werden, da POSIX nur diese Schnittstelle beschreibt. Die folgenden Daten wurden als notwendig für die Emulation befunden:
Die Umgebung bildet die Arbeitsumgebung des Prozesses. Sie kann vom
Nutzer mittels `export` (sh) bzw. `setenv` (csh) beliebig manipuliert
werden(1). Das gleiche gilt für die Argumente eines Prozesses. Sie
werden beim Aufruf des Systemrufs Exec auf dem Stack des Prozesses
abgelegt und sind damit frei manipulierbar. Diese beiden Elemente
können also im Adreßraum des Prozesses liegen.
Signalbehandlung
Die Daten der Signalbehandlung werden vom Nutzer mittels signal()
manipuliert. Hier gibt es lediglich die Einschränkung, daß das Signal
SIGKILL nicht behandelt oder ignoriert werden darf. Dieses Signal
ist die letzte Möglichkeit, einen Prozeß zu beenden. Es muß also von
der Implementation sichergestellt werden, daß dieses Signal behandelt
wird. Wird das garantiert, können die Daten im Adreßraum des Prozesses
liegen. Das zweite, wesentlichere Argument ist die Realisierung der
Signalbehandlung. Signale sollen von einem extra Thread behandelt
werden. Dieser muß in der Lage sein, zu entscheiden, ob ein Signal
zugestellt wird und wenn ja, wie es behandelt wird. Dazu muß er auf
die Informationen der Signalbehandlung zugreifen können.
Informationen über Prozeßhierarchie
UNIX-Prozesse werden auf L3-Tasks abgebildet. Aus den in [hier] angeführten Gründen ist ein zentraler Prozeß als
Vater aller UNIX-Prozesse notwendig. Dieser führt auch die
Prozeßhierarchie, deshalb kommen diese Daten in den Prozeßserver.
Andere Aspekte sind das Problem der verteilten Verwaltung dieser Daten
und die Sicherheit, da mit der Prozeßhierarchie auch Signale
verbunden sind (Status-Änderung des Sohns).
pid, process group, session, leader
Das aktuelle Verzeichnis eines Nutzers darf mittels `cd' bzw. dem Systemruf chdir() jederzeit vom Nutzer verändert werden. Es ist also unbedenklich.
Das Wurzelverzeichnis darf allerdings nur mit root-Rechten verändert
werden. Hier ist also eine Prüfung der Rechte notwendig, die zwar
innerhalb der Library durchgeführt werden kann, das neue Wurzelverzeichnis
darf dann aber nicht durch den Prozeß selbst manipuliert werden. Ein
Ansatzpunkt wäre eine Verwaltung des Wurzelverzeichnis bei einem Server
verbunden mit einer Pufferung innerhalb des Prozesses. Die Bibliothek kann
dann den kompletten Pfadnahmen zusammenbauen und der Fileserver hat
die Möglichkeit, die Angabe bei einem vertrauenswürdigen Server zu
prüfen.
Steuerterminal
Das Terminal, von dem Signale wie SIGTSTP(2), SIGTTIN(3) oder SIGTOUT(4) an den Prozeß gesendet werden können. Da diese Information
vom Terminalserver zum Senden von Signalen verwendet wird, darf sie
nicht fälschbar sein. Sie muß zentral geführt werden.
Filedeskriptoren
Filedeskriptoren z. B. werden mit open() erzeugt und mit
close() wieder vernichtet. Die Prüfung der Rechte erfolgt beim
open() durch einen Mechanismus innerhalb des Servers. Eine
Manipulation des zurückgelieferten Filedeskriptors zum Zwecke des
Zugriffs auf andere Objekte kann der Server jederzeit erkennen, wenn
sich ein Prozeß mit einem Deskriptor an ihn wendet, den er nicht
erzeugt hat. Es bestehen hier also keine Bedenken, diese Information
innerhalb der Task zu halten. Die dabei entstehenden
Konsistenzprobleme lassen sich mit Hilfe des in Kapitel[hier] geschilderten Prinzips lösen.
5.7.3 Zuordnung der Daten zu Prozeßserver und Emulationsbibliothek
Auf Grundlage der im vorangegangenen Kapitel gemachten Einschätzungen
werden die Daten wie folgt zugordnet: Daten innerhalb des Prozesses
Beim Aufruf eines fork() oder exec()-Systemrufs erben die Söhne bzw. neuen Programme einen Teil der Umgebung ihrer ,,Eltern''. Diese Informationen müssen in den Adreßraum der neuen Task übertragen werden. Aufgrund des Umfangs der Daten kommen hier nur die Nachrichtenelemente indirekter String und Datenraum in Frage. Die Wahl des geeigneten Mittels wird in der Implementation getroffen.
In den vorangegangenen Kapiteln wurden einige Fragen offengelassen,
da noch nicht alle Grundlagen zu ihrer Beantwortung vorhanden waren.
Diese Fragen sollen hier aufgegriffen und Lösungen dafür gesucht
werden. 5.8.1 fork()
Der Systemruf fork() erzeugt einen neuen Prozeß, der sich bis auf wenige Ausnahmen wie sein Vater verhält. Er erbt die Umgebung seines Vaters und alle offenen UNIX-Objekte. Dadurch entstehen zwei Probleme:
Das Erzeugen eines identischen Sohnprozesses ist bei dem gegebenen Speicherlayout unproblematisch. Der Standarddatenraum wird kopiert und daraus eine neue Task erzeugt. Hat das Programm aufgrund eines hohen Speicherbedarfs einen separaten Halde-Datenraum, muß dieser zusätzlich kopiert und an die neue Task gesendet werden.
Das größere Problem ist das Erben der Rechte an offenen Objekten. Hier müssen alle Server von der Existenz eines neuen Prozesses informiert werden, der nun gleichfalls Rechte an den Objekten besitzt. Diese Benachrichtigung sollte für jeden Server nur einmal erfolgen. Zusätzlich muß garantiert werden, daß der neue Prozeß seine erste Anforderung erst dann stellt, wenn der Vater-Prozeß mit der Benachrichtigung der Server fertig ist. Hier muß eine Synchronisation zwischen Vater- und Sohnprozeß stattfinden.
Der Ablauf eines fork()-Rufs ist in Abbildung [hier] dargestellt.
5.8.2 exec()
In der Diskussion des setuid-Problems blieb ein Problem offen. Wie wird gewährleistet, daß ein setuid-Programm nicht vom ausführenden manipuliert wird, um sich mehr Rechte zu verschaffen.
Betrachten wir folgende Situation: Ein unprivilegiertes Programm installiert mit Hilfe von L3-Kerndiensten einen Programmteil in seinem eigenen Adreßraum und sorgt dafür, daß dieses Kodestück später aktiviert wird(1). Dann führt es ein setuid-Programm aus, daß unter der uid eines privilegierten Nutzers läuft. Beim Aktivieren des Kodestücks ist die Task bei den verschiedenen Servern mit der neuen uid registriert und das Kodestück kann mit den umfangreicheren Rechten Schaden anrichten.
Da der Prozeß aufgrund des Autonomie-Prinzips von außen nicht kontrollierbar ist, kann dieses Herangehen nicht verhindert werden. Der einzige Punkt, an dem man sicher sein kann, daß keine Manipulation passiert ist, ist der Moment des Startens einer Task. Hier kann man sicher sein, dass die Task genau den Programmkode ausführt, der ihr im Standarddatenraum übergeben wurde. Deshalb erzeugt der Prozeßserver beim Ausführen eines setuid-Programms eine neue Task, die das Programm ausführt und schließt damit jede Manipulation von Seiten des ausführenden Programms aus. Das Abtreten der Rechte an offenen Objekten geschieht dann ähnlich wie bei einem fork()-Aufruf, nur daß hier der neue Prozeß alleiniger Eigentümer der Objekte ist. Der Ablauf ist in Abbildung [hier] dargestellt.
SIGKILL und SIGBLOCK dürfen laut POSIX vom Prozeß nicht ignoriert oder behandelt werden. In Anlehnung an die in den vorangegangenen Kapiteln gemachten Ausführungen kann man sagen, daß der einzige Weg dies zu erreichen die Behandlung außerhalb der Task ist. Deshalb wird die Behandlung dieser beiden Signale vom Prozeßserver übernommen. Er beendet im Falle von SIGKILL die Task und informiert alle Server über das Prozeßende. Informationen des Prozesses über offene Objekte können dabei nicht verwendet werden, da SIGKILL in der Regel an den Prozeß gesendet wird, wenn dieser nicht mehr auf eine normale Art beendet werden kann. Die Informationen des Prozesses sind dann mit hoher Wahrscheinlichkeit nicht korrekt und damit nicht verwendbar.
SIGBLOCK resultiert einfach in einem Blockieren der Task, die dann aus dem Scheduling herausgenommen wird, bis ein Deblockieren der Task aufgrund eines SIGCONT erfolgt.
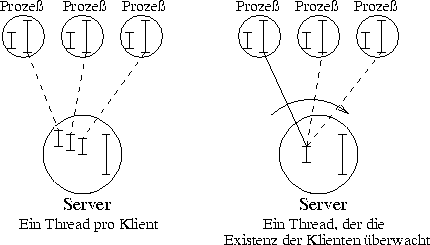 Überwachung aktiver Klienten
Überwachung aktiver Klienten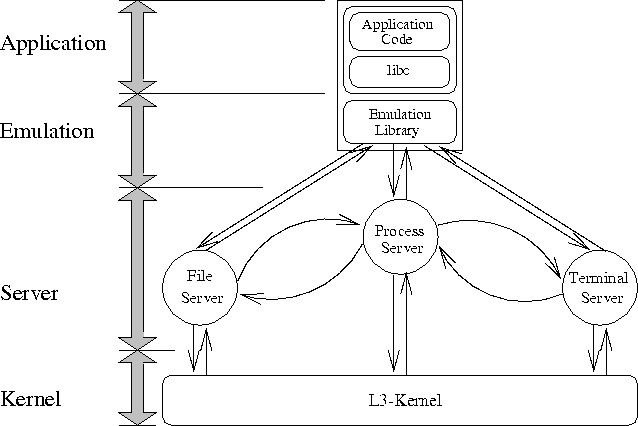 Struktur der UNIX-Emulation
Struktur der UNIX-Emulation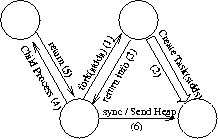 Das fork-Protokoll
Das fork-Protokoll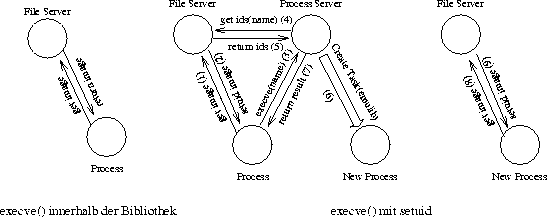 Das exec-Protokoll
Das exec-Protokoll