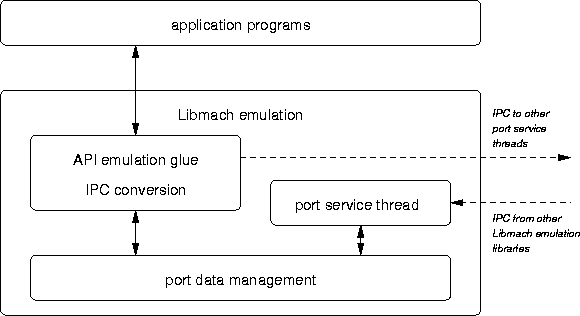
 Overall Structure of Libmach Emulation.
Overall Structure of Libmach Emulation.This chapter describes the various steps to be tackled to port Lites
to L3, and alternative approaches. 3.1 Steps Towards Porting Lites to L3
In this section, we will list the subtasks we've identified which will ultimately lead to our goal, a Lites implementation running on L3. All steps will be discussed in greater detail later in this chapter.
The following list is based on some of the findings of section [here], namely that Lites depends a lot on Mach ports, the C Threads Library and Mach's IPC facilities.
To resolve Lites' dependence on Mach's C Threads library, we've identified the following alternatives:
As discussed in section [here], the C Threads library provides user-level threads which it multiplexes onto Mach kernel threads. It provides a higher-level interface than the kernel thread interface.
The L3 kernel thread interface is comparable to Mach's. Both interfaces implement similar operations: creation and destruction of threads, and definition of a thread's properties. [5] [8]
To summarize, Option 3 would involve changing Lites to use a more lower-level interface, Option 2 would require emulation of Mach's low-level thread interface on L3's similar interface, and Option 1 means the re-implementation of a high-level interface.
We favour the second option (emulate Mach's kernel thread interface)
because we estimate it to be least expensive.
3.3 Ports Emulation
The central aspect of Libmach emulation is resolving Lites'
dependence on ports. As explained in section [here], Lites
depends on Mach's port functionality in various ways. 3.3.1 Alternatives
The advantage of a Lites implementation which doesn't require a port
layer seems obvious: A version of Lites optimized for L3's synchronous
message passing scheme promises much better performance than one which
requires an emulation layer. However, in section [here]
we've seen that Mach ports are utilized not just as communication
endpoints but for a great variety of purposes. It follows that doing
without ports would require a lot of changes to Lites; therefore,
we've refrained from this option.
External Server Vs. Task-local Port Emulation
The main advantage of having an external port emulation server as a self-contained L3 task is basically the same which holds for any multi-server solution: The solution is more modular, and components have better protection against each other. In our case, the clean separation of functionality traditionally provided in the Mach kernel into an external server would be an additional advantage: There would be only one entity which would need to parse Mach messages in order to manipulate (and protect) port rights and memory objects and translate port names from one task's namespace into another's.
On the other hand, the external server solution bears disadvantages. If the server were to provide port reference protection and port name translation, it would require sending every message twice: once when sending it to the server for approval and a second time when delivering it to the recipient. As L3 doesn't support lazy copying of random memory ranges(1), this incurs a performance hit. While the amount of copied data per sent message may be relatively small, it certainly sums up to considerable quantities because the extra copy happens at every system call via RPC to the Lites server.
The task-local port emulation solution avoids copying IPC data several times. However, it possesses a problem of its own: Each task would have to maintain its own port name space, i.e. port names and port references for all known ports. When updating port references for a task, the respective partners involved need to update their reference information: When transferring send rights, only the owner of the receive right must be informed, but when transferring receive rights, all send right owners need to be passed the new recipient information. The latter operation would be considerable cheaper when using a central server.
In practice, however, migration of receive rights between tasks is a
rare operation. We've analyzed the Lites code and found that it
doesn't use transfers of receive rights at all; thus, the reference
update problem doesn't apply to us. That's why we've decided to
implement the task-local emulation solution.
3.3.3 Design of the Port Emulation Library
The goal is to create a library which provides a subset of the Libmach API, namely the mach_port_* routines. Further objectives are efficiency and easiness. Starting with Lites' pattern of port use, we want to provide just the functionality Lites requires.
Overall Structure of Libmach Emulation. Overall Design
Figure [here] shows an overall sketch of the Libmach emulation design.
The port data management layer is the heart of the emulation library: It manages data structure bookkeeping and synchronization between the application and the library's port service thread and is discussed below in greater detail.
The port service thread handles incoming Mach IPC messages sent by instances of the Libmach emulation in other tasks.
The API emulation glue and IPC conversion layer does the real emulation work: transforming Mach IPC calls into L3 IPC (discussed below in section [here]), and emulate Mach kernel object manipulations using the port data management layer.
Furthermore (and not shown in the figure), the emulation library contains utilities for L3 virtual memory management, data structure locking, initialization and debugging aids.
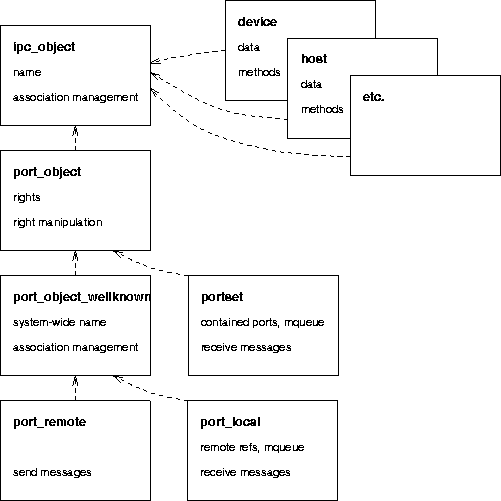 Class Hierarchy of Libmach (and Port) Emulation.
Class Hierarchy of Libmach (and Port) Emulation.
Design of the Port Data Management Layer
The port data management layer manages the data structures used for bookkeeping ports, port references and outstanding (queued) Mach messages.
It has been designed in object-oriented fashion. The rationale is that the respective portion of the Mach kernel has been designed in object-oriented fashion, too, and we tried to resemble their design as much as sensible.
Figure [here] shows part of the class hierarchy as implemented in the Mach kernel. We see that the tasks' port name spaces (ipc_space) contain references to members of ipc_object (or subclasses thereof). ipc_object is the internal notion of objects which are named by port names; they can be ports or port_sets. All other kernel objects (devices, hosts and so on) are basically implemented as subtypes of ports; they're controlled with specializations of the generic Mach IPC interface.
The class hierarchy as implemented in the Libmach emulation is shown in figure [here]. There are several differences to Mach's hierarchy:
In the special case when the sender of the receive right also holds the receive right to the port in question, this protocol can be short-circuited by a normal message send operation (as long as the port data structures remain locked by the sending thread).
Lites uses MIG-generated stubs, these in turn employ Mach IPC via
mach_msg. We have to enable Lites to use the L3-provided message
facilities instead. 3.4.1 Alternatives
We have seen in section [here] how the message transfer works in the Lites-on-Mach environment.
The main difference between the following alternatives is the level at
which the message flow is intercepted and the message is converted
from the Mach form into a L3-specific one. Using L3 IPC System Calls
All code fragments referring to IPC could be adapted manually in
order to interface to the L3 IPC system calls.
IPC Stub Generation
The IPC interfaces used by Lites are described by MIG interface
definition files. A stub generator could generate stubs that use L3
IPC instead of Mach's mach_msg.
mach_msg Emulation
All MIG-generated stubs call mach_msg. mach_msg is the only entry to
the kernel's IPC transmission facilities. So we could provide our own
mach_msg that converts its parameters and transmits the resulting
message using the L3 message transmission facilities.
3.4.2 Discussion
Using L3 IPC System Calls
We considered the technique of replacing the many occurences of Mach
IPC calls to be cumbersome and error-prone. As described in section
[here] Lites relies on Mach IPC features (especially ports
and port rights) that are not present in L3. This adds more complexity
to this approach.
Stub Generation Vs. mach_msg Emulation
The generated stubs replace the MIG-generated ones, so we don't need to add an additional layer, and we get rid of the inefficient MIG-generated stubs. Modern stub generator optimization techniques ([14] and [15]) should enable us to gain better performance than in the current MIG-using Mach setups.
Implementing such a sophisticated stub generator is beyond the scope of our work. The authors of the papers mentioned above work on a stub generator framework but the implementation is still in progress, therefore we refrained from using it yet.
The primary advantage of the mach_msg emulation approach is that the
messages will be intercepted at the lowest level. mach_msg is the
common point where every message has to pass through. On the other
hand this may be a substantial drawback because we have to add this
additional emulation layer and each message must be processed by this
layer. This can cause a considerable performance loss.
Message Encapsulation Vs. Message Transformation
In the Message Encapsulation approach the message to be transmitted contains a verbatim copy of the original message buffer. For some kinds of message components the plain content of the messge buffer is not sufficient (some of the data is only valid in the task's scope, e.g. port names). For these message components it is necessary to create auxiliary information and send this in addition to the verbatim buffer copy.
Message Transformation means that the message is converted at the message component level. Each message component has one (or sometimes) more converted counterparts; no message components share one.
The structure of a message differs substantially between L3 and Mach, so Mach has a great variety of message component types, whereas L3 only has a direct string, indirect strings and dataspaces. So e.g. all Mach integer, character and boolean message component types are mapped to L3 direct strings, and the Mach-specific type information is lost.
The mach_msg emulation does not know the structure of the Mach message in advance. In contrast the L3 syscall that waits for the message has to impose upper limits on the amount of message components of each type (direct, indirect etc.), because it has to provide preallocated receive buffers. The encapsulation gives us a structure of the L3 message that does not depend on the structure of the original Mach message, whereas a Mach message transferred via transformation would have to obey some arbitrary restrictions.
In the transformation approach each data element of a Mach message will be converted into a component of an L3 message. This allows more interoperability between programs using this mach_msg emulation and other L3 programs. It is questionable whether this improved interoperability is of practical use. In addition L3 requires the components of a message to appear in a certain order, so the transformation has to reorder the message components.
Regarding performance there seems to be no obvious difference, details depend on the actual implementation. The higher complexity of the transformation might cause some degradation, but we have no proof.
There seems to be no enormous difference in the amount of data that has to be copied; both methods can take advantage of passing references instead of copying everything.
We decided to implement message encapsulation because the previous decision of writing a mach_msg emulation (and the above-described receive-buffer problem) enforced this. The following design describes some details.
An alternative design using a stub generator and message transformation is outlined after that.
![]() Message transmission in the mach_msg emulation.
Message transmission in the mach_msg emulation.
3.4.3 Design
A general picture of the design is provided in figure [here]. Compared to the L3 (figure [here]) and Mach (figure [here]) architecture the higher complexity is due to two reasons: the port rights are handled in user space and therefore require additional conversions, and Mach's message queuing is moved into user space. The asynchronity is provided by an additional thread, the port service thread.
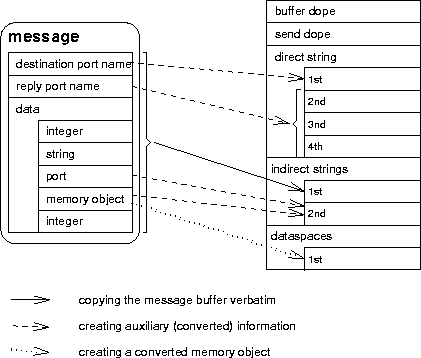 Message encapsulation example.
Message encapsulation example. Message Encapsulation
An example of a Mach message and its L3 counterpart created by encapsulation is shown in figure [here].
The port names must be converted to global unique names, because port names are only valid inside the task's scope. Currently the size of such a unique name is 12 byte, therefore it is stored in 3 direct string elements. If a unique name were much larger it would be appropriate to use a indirect string instead.(1)
The most similar component for a Mach memory object is a L3
dataspace. This isn't implemented because we didn't emulate Mach's VM
subsystem; reasons are described below (section [here]).
Port Service Thread
In Mach buffering is done in the kernel (see figure [here]). In L3 the message transfer is synchronous, therefore message buffering and queuing has to be provided in user mode. Similar to the signal handling thread in Lites [12] we designed a port service thread.
This thread receives all encapsulated Mach messages. According to their destination port the messages are copied into the appropriate queue and the thread starts receiving again.
The queues are part of the receiving task and are shared by the port service thread and the main thread. Access to the queues is mediated by a global lock.
The main thread and the port service thread may be synchronized by condition variables. Each message queue has a condition variable that represents the condition that a message is available in this queue. When the main thread invokes mach_msg, it finds the associated condition variable and starts waiting for the condition. When the port service thread received and queued a message for this queue it raises a signal for the queue's condition variable. The main thread then wakes up and dequeues the message.
The receive buffer has to be provided before the message has been
received. Therefore it is impossible to choose its size according to
the size of the message. The ideal solution might be to allocate a
very large buffer and truncate it after the message has been received.
3.4.4 Alternative Design
IPC Stub Generation
A new stub generator replaces MIG and its support library.
![]() Message transformation example.
Message transformation example.
Message Transformation
An example of a Mach message and its L3 counterpart created by translation is shown in figure [here].
The mapping of the Mach message components to L3 message components is
quite straightforward: all integer, character and boolean values are
mapped to direct strings, the strings are mapped to indirect strings.
Combining IPC stub generation and Message Transformation
Message transformation causes the resulting messages to have a variable number of message elements. Therefore IPC stub generation should be used. All IPC definitons for one interface (all messages that a thread should be able to receive) must be known to the stub compiler in order to compute the maximal number of each message component types.
Converting messages by transformation is more complex. Stub generation moves this overhead from run-time to compile-time, so the impact on IPC performance is lowered.
As we've seen in section [here], Mach's and L3's VM schemes posses both similarity and differences: While the concepts implemented are quite similar, the methods to interface them differ a lot.
Lites utilizes the following portions of Libmach's VM interface:
As both of these interfaces are pretty complex, our general design
goal was to emulate only the semantics required by simple RPC-using
servers and clients and otherwise to modify Lites to use the much
simpler L3 interfaces. 3.5.1 External Pager Interface
In order to allow a Mach memory manager to run on L3 without modification, and a client program to use Mach's vm_map interface to attach to a memory manager, emulation glue code would be required to implement solutions to the following problems:
All in all, accurate emulation of Mach external pager semantics introduces a large overhead on L3's memory management.
That's why we've decided to do without emulation of Mach's pager
interface. Instead, Lites should be modified to employ L3's memory
management scheme directly. (The Lites server code which requires
modification is well-discriminated already because of a large
#ifdef which accounts for different implementations for different
versions of the Mach kernel.)
3.5.2 Memory Region Manipulation Interface
As we've stated earlier, L3 does not provide a global interface to operate on random virtual memory regions; instead, region management is carried out entirely within memory managers. Thus, clients wishing to change the semantics associated with a given memory region must communicate directly with their memory manager.
Generally, an emulation library running under L3 can not keep track of which memory region is backed by which memory manager, except if the emulated program always uses interfaces provided by the library to manipulate memory regions. In the case of random emulated Unix binaries, this can not be guaranteed, so it is a bad idea to rely on it.
That's why we chose to emulate only the most common memory region manipulation routines: vm_allocate to allocate some memory from the standard memory manager, and vm_deallocate to deallocate previously vm_allocate'd memory (a serious restriction with respect to Mach's original vm_deallocate semantics, which are to unmap a random memory region, not limited to previously vm_allocate'd memory regions).
We designed an Unix-sbrk-like interface which provides objects called heap spaces (based on data spaces) and a method to sequentially allocate memory blocks from them, and we ported FreeBSD's malloc library routine to operate on such heap spaces, forming a heap. Our Libmach emulation's initialization code allocates two heaps on startup: One for library-internal data management (e.g. for the port data management layer), and one for serving the emulated program's vm_allocate requests.
The intended implementation language is C, therefore the availability of a C compiler and corresponding tools (linker, usually an assembler) is essential. A way of integrating program parts written in assembler is required in order to implement certain low-level functions not available in C and to test and evaluate optimized code for performance-critical sections.
The development environment must be designed to provide a method for handling private source code files against a common source tree.
Some members of the research group are used to GNU Emacs, so there
should be a way for using it as editing framework. A version control
system is optional but highly desired in order to coordinate the
collaboration.
3.6.2 Programs
The Gcc (the GNU C Compiler) is a high quality C/C++ compiler. Its source code is freely available and it can be built on all major Unix-like operating systems.
Together with the GNU Binutils, a set of assembler, linker, and other tools, it can be used to create a cross compilation environment. This enables us to create programs for an operating system that isn't stable enough yet to host the Gcc/Binutils tool chain itself. When we have a running and stable Unix environment on L3 we can built native versions of these development tools by recompiling them using the cross compiler.
This development tool chain is already successfully used by other operating system research groups, and its quality is even sufficient to be used by commercial Unix vendors.
CVS (the GNU Concurrent Versions System) is a version control
system. CVS stores all files in a centralized repository. Each
developer has one (or more) private copies of a source tree stored in
this repository. During development changes are made in these private
files. After testing these changes are submitted to the repository.
3.6.3 Possible Approaches
L3-delivered Tools
L3 provides Gcc version 1.37. This version is quite antiquated but usable.
The source code management was done by synchronizing the private copies manually and transferring the files either by floppy or via a TCP/IP connection and ftp.
CVS must be used in the Unix-based environment. Since version 1.5 CVS has an
integrated mechanism for communicating with a CVS server via TCP/IP. A
port of the CVS Client to L3 should be feasible, but we cannot foresee
the pitfalls-to-be.
DOS-based development
L3 comes with an integrated DOS box. A DOS-based cross development would enable developers to run the cross-development concurrently to L3. Please note that this approach wasn't taken into consideration when the decision was made because a viable option for creating a critical component (the access to a common source tree) was not available at this time. Nevertheless this section shows a route through an alternative approach.
DJGPP is a C/C++ development toolbox consisting of DOS ports of gcc 2.x, GNU Binutils and GNU Make. There exists a version that creates a.out programs, so the steps needed for running its output on L3 should be similar to the ones described for the UNIX-based case. DJGPP uses the DPMI interface, so the DOS facility must provide this. DOSEMU (the DOS emulator for Linux and NetBSD) provides DPMI in an protected operating system, so this need not break security. We expect kernel modifications to be necessary.
A sufficient variety of editors is available for DOS. There is even a DOS port of a recent GNU Emacs.
When the DOS box allows communication via TCP/IP it is possible to run
a not-yet-existing port of the CVS client in it. Otherwise we could
try to port the CVS client to native L3.
Unix-based cross development
The GNU C Compiler and the GNU Binutils can be used to create a cross development environment. CVS is already available.
The compiled programs must be transferred to a machine running
L3. The most automatic way is to transfer these files via FTP.
3.6.4 Decision
We decided to create a Unix-based cross development environment because it required the smallest amount of work and provided the most comfortable development environment.
The Linux a.out binary format was chosen because of its simple but sufficient structure.
(There are plans to use ELF on L3, but the ELF tools are not stable
enough yet and ELF is more powerful, and hence complicated, than a.out.)
3.6.5 Running the compiled programs
The first approach was to compile and link the program using the cross tools. A loader was written (by another member of our group) that runs Linux-compiled a.out programs.
Another approach is to link the object files on L3 against the L3-provided Libc. This enables us to use the Libc on L3.
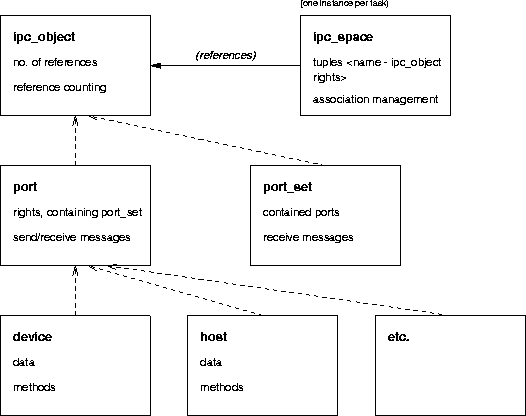 Class Hierarchy of Port Implementation in Mach Kernel. Each
box lists a class name, the specific data that objects of these
classes hold, and typical methods applied to members of the class
Class Hierarchy of Port Implementation in Mach Kernel. Each
box lists a class name, the specific data that objects of these
classes hold, and typical methods applied to members of the class