[ Class Overview ] [ Assembler Crash Course ]
Assembler Crash Course (x86-64)
Content
- What is the goal of this crash course?
- What is an assembler?
- What can an assembler do?
- What is a register?
- What is memory?
- What is a stack?
- Addressing modes
- Procedures
- Volatile and non-volatile registers / Link to C
What is the goal of this crash course?
The goal of this crash course is to give an overview of assembly language programming, especially for OSC participants who do not yet have any assembly knowledge.
We don't expect you to be able to write complex assembler programs at the end, since you don't need to. However, we hope that this will give you at least some idea of what a high-level language program looks like in assembler, and that you will be able to write very small assembler functions yourself if given the appropriate help.
The different concepts are explained using the x86_64 processor as an example. This processor architecture is also known as amd64 or x64, comes from the companies Intel and AMD and can be found directly or as a replica in almost every modern PC. The notation used corresponds to the Netwide Assembler NASM, which is also used in the development of the exercise operating system OOStuBS.
The "framework" of an assembler program is not explained here, you can see it best in an assembler file.
What is an assembler?
Strictly speaking, an assembler is a compiler which translates the code of an "assembler program" into machine code, i.e. zeros and ones. Unlike a C compiler, however, the assembler has it very easy, since (almost always) one assembler instruction corresponds to exactly one machine code instruction. The assembler program is therefore only a representation of the machine program which is (somewhat) more comfortable for humans:
Instead of
01001000 00000101 11101000 00000011the programmer can use the assembler instruction
add rax,1000which (for the x86_64 processors) means exactly the same thing:
| Symbolic description | Machine code |
|---|---|
| add rax | 0100100000000101 |
| 1000 (dec.) | 0000001111101000 |
(Additionally the assembler swaps the order of the bytes of the offset)
| 0100100000000101 | 11101000 | 00000011 |
| add rax | low Byte | high Byte |
In common language usage, the term "assembler" is understood less as the compiler than as the symbolic notation of the machine language. add rax,1000 is then an assembler instruction.
What can an assembler do?
An assembler can actually do very little, namely only what the processor understands directly. All the nice constructs of higher programming languages, which allow the programmer to transfer his algorithms into understandable, (fairly) error-free programs, are missing:- no complex statements
- no comfortable for, while, repeat-until loops, but almost only gotos
- no structured data types
- no subprograms with parameter passing
- ...
-
The C-Statement
sum = a + b + c + d;
is too complicated for an assembler and must therefore be split into several instructions. The x86_64 assembler can only add two numbers and store the result in one of the two "variables" (accumulator register) used. The following C program is therefore more like an assembler program:sum = a; sum = sum + b; sum = sum + c; sum = sum + d;and would look like this in assembler:mov rax,[a] add rax,[b] add rax,[c] add rax,[d] -
Simple if-then-else constructs are already too difficult for
assemblers:
if (a == 4711) { ... } else { ... }and must therefore be expressed using gotos:if (a != 4711) goto unequal equal: ... goto break: unequal: ... break: ...In the x86_64 assembler it looks like this:cmp rax,4711 jne unequal equal: ... jmp break unequal: ... break: ... -
Simple counting loops are better supported by the processor. The following C program
for (i=0; i<100; i++) { sum = sum + a; }looks like this in assembler:mov rcx,100 continue: add rax,[a] loop continueThe loop instruction implicitly decrements the rcx register and executes the jump only if the register content is not 0 afterwards.
What is a register?
In the examples mentioned so far the names of registers were always used instead of the variable names of the C program. A register is a tiny piece of hardware inside the processor which can store up to 64 bits, i.e. 64 digits in the range 0 and 1, in x86_64.
x86_64 CPUs have the following registers:
| General-purpose registers | |
|---|---|
| Name | Comment |
| rax | general purpose, special meaning for Arithmetic commands |
| rbx | general purpose |
| rcx | general purpose, special meaning for loops |
| rdx | general purpose |
| rbp | base pointer |
| rsi | source for string operations |
| rdi | destination for string operations |
| rsp | stack pointer |
| r8 bis r15 | general purpose |
| Segment registers | |
|---|---|
| Name | Comment |
| cs | code segment |
| ds | data segment |
| ss | stack segment |
| es | any segment |
| fs | any segment |
| gs | any segment |
| Other registers | |
|---|---|
| Name | Comment |
| rip | instruction pointer |
| rflags | CPU status |
In addition, there are the 64-bit floating-point registers MMX0 to MMX7 and the 128-bit SEE registers XMM0 to XMM15, but we do not use them here.
The lower bytes of the registers rax, rbx, rcx and rdx have their own names, also the 32bit parts of rbp, rsi, rdi, rsp, rflags and rip can be used this way. For the register rax, for example, it looks like this:
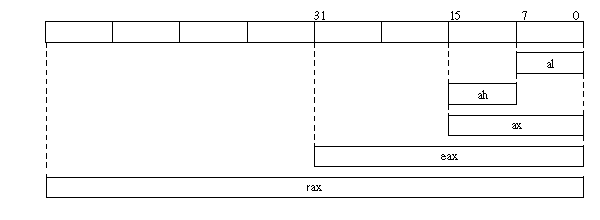
What is memory?
Most of the time, the registers are not enough to solve a problem. In this case, the main memory of the computer must be accessed, which can store considerably more information. To the assembler programmer, the main memory looks like a huge array of registers that are 8, 16, 32 or 64 bits "wide" as needed. So the smallest addressable unit is a byte (= 8 bits). Therefore, the size of the memory is also measured in bytes. In order to access a specific entry of the "main memory" array, the programmer must know the index, i.e. the address of the entry. The first byte of the main memory gets the address 0, the second the address 1 and so on.
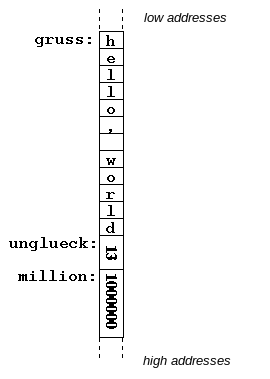
In an assembler program, variables can be created by assigning a label to a memory address and reserving memory space of the desired size.
[SECTION .data]
gruss: db 'hello, world'
unglueck: dw 13
million: dd 1000000
[SECTION .text]
mov ax,[million]
...
|  |
What is a stack?
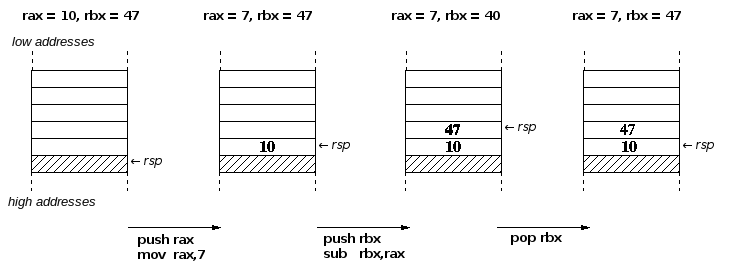
You don't always want to think up a new label just to store the value of a register for a short time, for example, because you need the register for a certain instruction but don't want to lose the old value. In this case you want something like a notepaper. You get it with the stack. The stack is actually nothing more than a piece of main memory, except that fixed addresses are not used there, but the data to be saved is simply always written to the top (push) or fetched from the top (pop).
So the access is quite simple, provided that one remembers in which
order the data was put on the stack. A special register, the
stack pointer rsp always points to the top element of the stack. Since push
and pop can only transfer 64 bits at a time, the stack is shown eight
bytes wide in the following figure.
Most instructions can take their operands either from registers, from memory or directly from a constant. With the mov instruction (among others) the following forms are possible, where the first operand always specifies the destination and the second always the source of the copy action:
- Register addressing: The value of one register is transferred to another.
mov rbx,rdi - Immediate addressing: The constant is transferred into the register.
mov rbx,1000 - Direct addressing: The value that is at the specified memory
location is transferred to the register.
mov rbx,[1000] - Register indirect addressing: The value that is at the memory location specified by the second register is transferred to the first register.
mov rbx,[rax] - Base register addressing: The value located at the memory location
specified by the sum of the contents of the second register and
the constants is transferred to the first register.
mov rax,[10+rsi]
Note: If the x86 processor operates in real mode (e.g. when working with the MS DOS operating system), memory addresses are specified by a segment register and an offset. But here this is not necessary (it is even wrong), because OOStuBS runs in long mode and the segment registers have already been initialized for you by us.
Procedures
From the higher programming languages the concept of the function or procedure is known. The advantage of this concept over a goto is that the procedure can be called from any point in the program and the program is then continued at exactly the point that follows after the procedure call. The procedure itself does not need to know from where it was called and where it continues afterwards. This is done automatically somehow. But how?
The solution is that not only the data of the program, but also the program itself resides in main memory, and thus each machine code instruction has its own address. In order for the processor to execute a program, its instruction pointer must point to the beginning of the program, so the address of the first machine code instruction must be loaded into the special register instruction pointer rip. The processor will then execute that instruction and, normally, will then increment the contents of the instruction pointer by the length of the instruction in memory so that it points to the next machine instruction. In the case of a jump instruction, the instruction pointer is not incremented or decremented by the length of the instruction, but by the specified relative destination address.
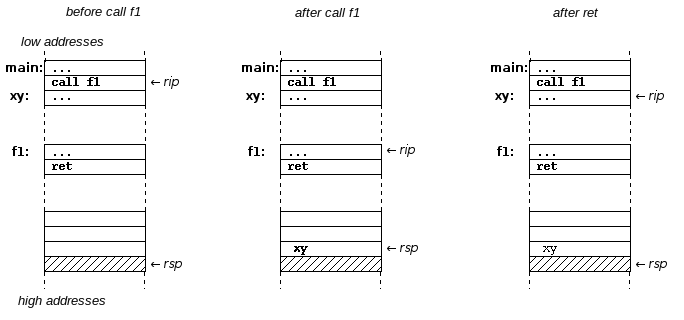
To call a procedure or function (the same in assembler), the method is the same as for a jump instruction, except that the old value of the instruction pointer (+ length of the instruction) is written to the stack beforehand. At the end of the function, a jump to the address stored on the stack is then sufficient to return to the calling application.
In the x86 architecture, storing the return address on the stack is done implicitly using the call instruction. Similarly, the ret instruction also implicitly performs a jump to the address located on the stack:
; ----- Main program -----
;
main: ...
call f1
xy: ...
; ----- Function f1
f1: ...
ret
If the function should receive parameters, these are partially passed on via CPU registers and partially via the stack, depending on the calling convention used. Here we use the System V AMD64 ABI, which is common on unix like systems, specifying that the first six arguments are in the registers rdi, rsi, rdx, rcx, r8 and r9 and all other arguments (if any) are on the stack. A function call with two arguments then looks like this, for example:
mov rdi, rax ; first parameter for f1 (from rax)
mov rsi, rbx ; second parameter for f1 (from rbx)
call f1
If the stack is used, the arguments must of course be removed there
afterwards. This is done either with pop or by directly
relocating the stack pointer.
; ... the first six parameters are in registers
push rax ; seventh parameter for f1 (from rax)
push rbx ; eighth parameter for f1 (from rax)
call f1
add rsp, 16 ; remove two parameters from the stack
The first six parameters can be accessed within the function directly
via the registers. If a function needs seven or more parameters, the
base pointer rbp is typically used. If it is saved right at the beginning of
the function and then assigned the value of the stack pointer, the
seventh parameter can always be accessed via [rbp+16], the eighth via
[rbp+24], and so on. This is independent of how many
push and pop operations have been used since
the beginning of the function.
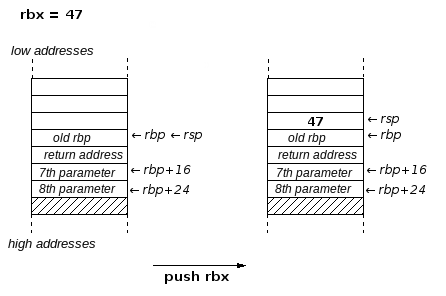
f1: push rbp
mov rbp,rsp
...
mov rbx,[rbp+16] ; load 7. parameter into rbx
mov rax,[rbp+24] ; load 8. parameter into rax
...
pop rbp
ret
Volatile and non-volatile registers / Link to C
To allow functions to be called from different places in the assembler program, it is important to specify which register contents may be changed by the function and which must still (or again) have the old value when the function is exited. Of course, the safest way is to basically store all needed registers on the stack at the beginning of the function and to reload them immediately before exiting the function.However, the assembler programs generated by the GNU C compiler follow a slightly different strategy: They assume that many registers are only used for a short time anyway, for example as count variables of small loops or to write the parameters for a function to the stack. Here, it would be pure waste to laboriously save the already long outdated values at the beginning of a function and restore them at the end. Since you can't tell from looking at a register whether its contents are valuable or not, the developers of the GNU C compiler simply decided that the registers rax, rcx, rdx, rdi, rsi, r8, r9, r10 and r11 are basically to be considered volatile registers whose contents may simply be overwritten. The register rax has a special role: It provides the return value of the function (if required). The values of the other registers, on the other hand, must be saved before they may be overwritten by a function. They are therefore called non-volatile registers.