 Copy-In/Out mit Einblenden des Nutzeradreßraums im Kern
Copy-In/Out mit Einblenden des Nutzeradreßraums im KernZiel dieser Arbeit war es, den Linux-Kern auf den Mikrokern L4 zu portieren, so daß er selbst als Anwendungsprogramm im Nutzer-Modus läuft. Dabei war eine 1:1-Binärkompatibilität mit der Linux-Originalimplementation (im folgenden Linux/i386 genannt) anzustreben.
Ein wichtiger Gesichtspunkt beim Entwurf war der Wunsch, möglichst viel Code von Linux/i386 zu übernehmen: Alle i386-Gerätetreiber sollten auch unter Linux/L4 funktionieren, und die Änderungen an den architekturunabhängigen Teilen des Linux-Kerns waren zu minimieren.
Die außerordentlich gute Leistung des Mikrokerns L4 (vgl. Abschnitt [hier]) erlaubt beim Entwurf eine ,,natürliche'' Herangehensweise. Im Gegensatz zu anderen Arbeiten sind daher spezielle Einschränkungen oder ein Binden des Codes der Unix-Emulation in den Adreßraum des Mikrokerns nicht nötig. Stattdessen ist es möglich, von den von L4 gebotenen Mitteln schöpferisch Gebrauch zu machen:
Linux-Gerätetreiber erwarten vom Linux-Kern eine bestimmte Umgebung, zu der auch die von der Architekturanpassung bereitzustellende Interruptverwaltung gehört.
(Wenn wir im folgenden von ,,Interrupts'' sprechen, so meinen wir von
externen Geräten erzeugte Hardware-Interrupts (IRQs), und nicht
Software-generierte Interrupts, die zum Kerneintritt führen; letztere
werden im Abschnitt [hier] besprochen.) 3.2.1 Annahmen der architekturunabhängigen Linux-Module
Top Halves sind kleine Programm-Fragmente, die sofort nach Eintreffen des Interrupts abgearbeitet werden. Sie sind nur durch andere Top Halves unterbrechbar und sollten daher recht schnell abzuarbeiten sein. In der Regel bestätigen Top Halves den Interrupt einem externen Gerät und markieren dann eine oder mehrere Bottom Halves zur Ausführung.
Anschließend werden die markierten Bottom Halves abgearbeitet, wenn keine anderen Top Halves mehr ausgeführt werden. Sie führen normalerweise interrupt-ausgelöste, aber zeitunkritische Programm-Fragmente aus.
Die Einhaltung der folgenden Semantik wird vorausgesetzt: Top- und Bottom-Half können nur durch Top-Halves neu auftretender Interrupts unterbrochen werden, nie durch weitere Bottom-Halves oder ,,normalen'' Kern-Code. (Dies bedeutet auch, daß während der Abarbeitung von Interrupt-Behandlungsroutinen kein Scheduling stattfinden kann.)
L4 stellt Interrupts einem bestimmten Empfängerthread als Nachrichten zu. Um solche Interrupt-Nachrichten zu empfangen, muß sich der Empfänger zuvor über den L4-IPC-Mechanismus an die Interrupt-Quelle ,,anschließen''. [15]
Da L4 jedem Thread nur den Anschluß an maximal eine Interrupt-Quelle gestattet, muß für jeden Hardware-Interrupt ein separater Thread gestartet werden.
Unmittelbar nach dem Empfang der Interrupt-Nachricht muß die
Interrupt-Verwaltung die Top Half der Interrupt-Behandlungsroutine
abarbeiten. Dies kann sofort im jeweiligen Interrupt-Thread erfolgen;
eine Serialisierung der Abarbeitung der Top Halves verschiedener
Interrupts ist nicht notwendig, da Linux die Möglichkeit der
Unterbrechung von Interrupt-Behandungsroutinen durch neue Interrupts
explizit vorsieht.
3.2.3 Bottom Halves
In Linux dürfen Top Halves nicht für die Abarbeitung von Bottom Halves unterbrochen werden; andersherum ist die Unterbrechung der Abarbeitung einer Bottom Half durch einen Interrupt mit zugehöriger Top Half sehr wohl möglich. Konzeptionell stellen daher die Bottom Halves eine von den Interrupts unabhängige Aktivität dar.
Um diese Semantik zu implementieren, stellt Linux das Semaphor intr_count zur Verfügung, das bei jeder Interrupt-Behandlung durch Top Halves erhöht werden muß; Bottom Halves dürfen nur abgearbeitet werden, wenn das Semaphor auf 0 steht.
Die Bottom Halves könnten innerhalb verschiedener Aktivitäten ausgeführt werden:
Die erste Lösung hat den Vorteil, daß sie die Linux-Semantik automatisch bereitstellt; außerdem führt sie zu einer einfacheren Implementation. Allerdings führt diese Lösung auch zu einer größeren Interrupt-Latenz, da unter Umständen noch mehrere Bottom Halves ausgeführt werden müssen, ehe der beteiligte Thread wieder Interrupt-Nachrichten empfangen kann.
Die zweite Lösung hat dieses Latenz-Problem nicht. Außerdem unterstützt sie auch Gerätetreiber, deren Bottom-Halves auf Interrupts (und Abarbeitung der zugehörigen Top Half) blockierend warten, wie beispielsweise der Tastatur-Treiber.
Ein potentielles Problem dieser Lösung ist jedoch, daß sie nicht auf Maschinen mit mehr als einem Prozessor funktioniert. Dafür müßte genaugenommen der Linux-Code reorganisiert werden, so daß die bisherige Linux-Semantik (Top Halves nicht unterbrechbar) nicht mehr garantiert werden muß. Die SMP-Variante von Linux/i386 umgeht das Problem bisher, indem der gesamte Kernzugriff (inklusive Interrupt-Behandlung) durch ein globales Lock synchronisiert wird; ein ähnlicher Workaround wäre auch für Linux/L4 denkbar.
Wir werten die Unterstützung von mehr Gerätetreibern und eine
geringere Interrupt-Latenz höher als eine einfache Implementation und
entscheiden uns daher für die zweite Variante.
3.2.4 Synchronisierung der Interrupt-Aktivitäten
Linux gewährleistet den Interrupt-Behandlungsroutinen (Top und Bottom Half), daß während ihrer Abarbeitung kein ,,normaler'' Linux-Kern-Code abläuft. Um diese Semantik unter L4 bereitzustellen, bieten sich folgende Möglichkeiten an:
Die erste Variante entspricht der Implementation in Linux/i386-SMP und wurde im vorigen Abschnitt bereits kurz diskutiert. Sie hat den Vorteil, daß sie auch mit mehr als einer CPU funktioniert, allerdings auf Kosten der Interrupt-Latenz.
Variante 2 funktioniert auf Multiprozessormaschinen nicht ohne
weiteres. Im Sinne einer besseren Interrupt-Latenz entschieden wir
uns jedoch für diese Variante, zumal es noch keine L4-Implementation
für Multiprozessormaschinen gibt.
3.2.5 Wechselseitiger Ausschluß durch cli()
In Linux/i386 wird wechselseitiger Ausschluß innerhalb kritischer Abschnitte im allgemeinen durch Löschen des Interrupt-Enable-Flags im CPU-Status-Register realisiert (implementiert durch die Operation cli()). Dies wäre prinzipiell auch in Linux/L4 möglich, da L4 privilegierten Tasks den Zugriff auf den entsprechenden Teil des CPU-Statusworts gestattet.
Allerdings gibt es unter L4 ein zusätzliches Problem, das diesen Ansatz unmöglich erscheinen läßt: Seitenfehler führen in L4 zur Umschaltung zu einem Pager-Thread und unter Umständen zum Aufruf des L4-Schedulers. Das kann dazu führen, daß Threads trotz cli() unterbrochen werden und kein wechselseitiger Ausschluß mehr stattfindet.
Um einen wechselseitiger Ausschluß mittels cli() dennoch zu realisieren, ergeben sich folgende Möglichkeiten:
Variante 1 ist leider nicht unproblematisch realisierbar; nähere Informationen dazu folgen im Abschnitt zur Speicherverwaltung.
Die zweite Variante hätte den Vorteil, daß sie unter Umständen sogar schneller als der Maschinenbefehl cli ist [21]. Ihre Realisierung ist jedoch etwas komplizierter. Problematisch ist sie in Fällen, in denen Gerätetreiber cli() nicht für einen wechselseitigen Ausschluß rufen, sondern um während der Programmierung des Interrupt-Controllers (PIC) keinen Interrupt zuzulassen.
Wegen der Realisierungsprobleme der ersten Variante entschieden wir uns gegen sie. Um Probleme mit der PIC-Programmierung zu umgehen, ruft unsere cli()-Realisierung zunächst außer dem Setzen des Interrupt-Locks auch noch den Maschinenbefehl ,,cli'' auf. Später sollte der relevante Linux-Code so modifiziert werden, daß er an entsprechender Stelle selbst den ,,cli''-Maschinenbefehl ausführt.
Linux-Prozesse stellen in einem Linux-System geschützte Entitäten dar. Sie sollen nur durch Systemrufe Zugriff auf Daten anderer Prozesse oder des Linux-Kerns erhalten können. Daher müssen sie in einer L4-Task gekapselt werden, da dies die einzige Möglichkeit in L4 ist, den Adreßraum einer Aktivität vor anderen Aktivitäten zu schützen.
Ein Linux-Prozeß besteht unter Linux/L4 also aus einer
Nutzer-Aktivität in einer separaten Task und einer zugehörigen
Kern-Aktivität (deren Modellierung im nächsten Abschnitt besprochen
wird).
3.3.3 Kern-Aktivitäten
Wie oben erwähnt können sich Kern-Aktivitäten durch Aufruf der Funktion schedule() suspendieren, was zur Sicherung des Kern-Kontexts und zur Umschaltung zur Kern-Aktivität einer anderen Linux-Task führt.
Die Kern-Kontexte können auf verschiedene Weise implementiert werden:
In der ersten Variante können Suspendierung und Aufwachen durch den L4-IPC-Systemdienst implementiert werden. Der Nutzeradreßraum kann permanent in den Adreßraum der Kern-Aktivität eingeblendet werden, und er wird bei einem Kontextwechsel automatisch mitumgeschaltet. Das führt zu einer besonders einfachen Copy-In/Out-Implementation: im wesentlichen eine Speicher-Kopieroperation.
Die zweite Variante hat den Vorteil eines schnelleren Kontextwechsels, da keine Adreßraumumschaltung erforderlich ist. Sie ist jedoch durch die L4-Implementation begrenzt, die nur 128 Threads pro Task erlaubt.
Dieses Problem hat die Variante 3 nicht. Außerdem ist ihr Kontextwechsel noch schneller, da dazu oft kein Eintritt in den L4-Kern nötig ist. Die Implementation des User-Level-Thread-Pakets könnte zunächst einfach aussehen, da Linux derzeit nur eine Kern-Aktivität zu einer Zeit unterstützt; somit würde nur ein L4-Thread benötigt, und die Synchronisation zwischen den User-Level-Threads gestaltete sich besonders einfach.
Die dritte Variante ist der zweiten also vorzuziehen. Die
Entscheidung zwischen den Varianten 1 und 3 ist jedoch auch vom Design
des Copy-In/Out-Mechanismus abhängig; wir verschieben sie daher bis
Abschnitt [hier].
3.3.4 Scheduling
Um Nutzer-Aktivitäten Prozessorzeit zuzuteilen, besitzt Linux einen Scheduler, der eine Linux-spezifische Scheduling-Strategie umsetzt.
Natürlich enthält auch der Mikrokern L4 einen Scheduler. Die Frage ist, ob und wie man die Linux-Strategie mit dem L4-Scheduler durchsetzen kann.
Variante 2 führt zu geringeren Kosten bei einer Präemption, da der Linux-Scheduler nicht aktiviert werden muß. Allerdings ist es mit dieser Variante nicht möglich, die Linux-Scheduling-Strategie direkt durchzusetzen, da L4 nur statische Prioritäten unterstützt; ein Nachbilden der Linux-Strategie durch beständiges Ändern der L4-Prioritäten ist nur mit großem Aufwand möglich.
Variante 1 erlaubt ein einfaches Durchsetzen der Linux-Scheduling-Policy, was unbedingt wünschenswert ist.
Leider waren zum Entwurfszeitpunkt Preemption Handler noch nicht
einsatzbereit, so daß wir zunächst die serverbasierte Variante
wählten.
3.4 Speicherverwaltung und Copy-In/Out
3.4.1 Annahmen der architekturunabhängigen Linux-Module
Damit die Gerätetreiber den physischen Speicher mit physischer =
virtueller Adresse adressieren können, muß für alle
Kern-Aktivitäten der RAM idempotent in den virtuellen Speicher
eingeblendet werden. Die Nutzung der Segmentierungshardware der
Intel-CPU-Architektur zu diesem Zweck ist nicht möglich, da L4 dies
nicht unterstützt.
3.4.3 Virtueller Speicher
Speicherseiten, die von Linux' Speicherverwaltung mit der zu implementierenden Seitentabellen-Schnittstelle [19] in die Seitentabelle eingetragen werden, müssen in den jeweiligen virtuellen Adreßraum eingeblendet werden. Da eine L4-Task sich nicht selbst Seiten einblenden kann, ist dazu eine Pager-Task erforderlich. Diese erwartet Seitenfehler (oder entsprechende RPCs), schlägt die entsprechende Seite in der aktuellen Seitentabelle nach und sendet sie als Flexpage zurück. [15]
Pager für Nutzer-Tasks kann der Thread der entsprechenden
Kern-Aktivität sein. Da aber auch der Linux-Kern intern virtuellen
Speicher benutzt, ist eine weitere externe Pager-Task erforderlich
(siehe Abbildung [hier]).
3.4.4 Copy-In/Out
Copy-In/Out ist der Linux-Mechanismus zum Kopieren von Daten in den Nutzeradreßraum hinein bzw. aus diesem heraus. Die Implementation dieses Mechanismus sollte besonders effizient ausfallen, da er häufig benutzt wird.
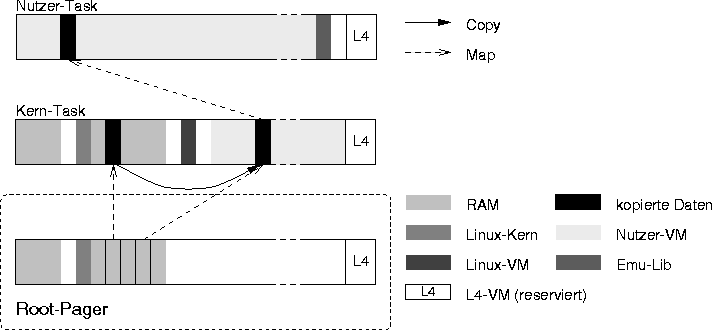
Copy-In/Out mit Einblenden des Nutzeradreßraums im Kern
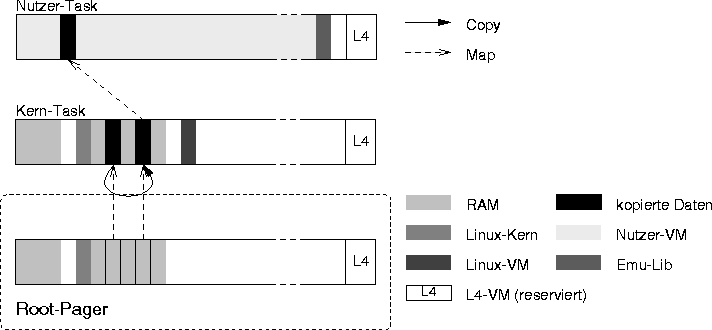 Copy-In/Out direkt in die Kachel
Copy-In/Out direkt in die Kachel
Folgende Möglichkeiten zur Realisierung dieses Mechanismus ergeben sich:
Linux/i386 erlaubt einen Nutzer-Adreßraum mit gültigen Adressen zwischen 0 und 0xbfffffff. Im Kern ist ab Adresse 0 der gesamte RAM und dahinter der kern-interne virtuelle Speicher eingeblendet; dahinter könnte der Nutzeradreßraums eingeblendet werden, etwa zwischen 0x20000000 und 0xdfffffff.
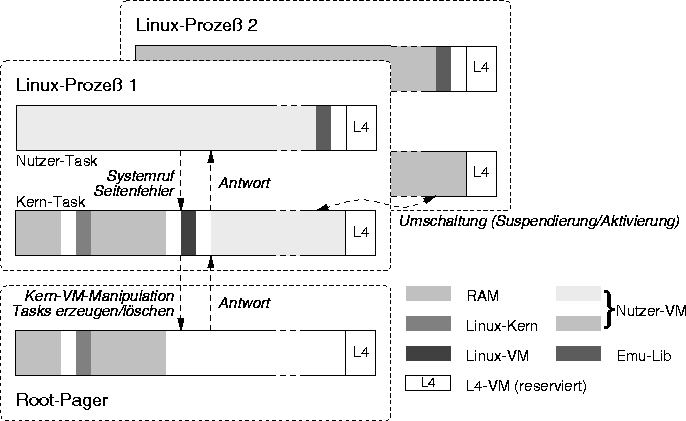 Aufbau der Adreßräume im Server-Tasksystem
Aufbau der Adreßräume im Server-Tasksystem
Die erste Variante (siehe Abb. [hier]) ist einfach zu implementieren, denn die Linux/i386-Implementierung kann weitestgehend übernommen werden: Copy-In/Out sind im Grunde Speicherkopieroperationen und lösen für nicht (oder mit unpassendem Zugriffsattribut) eingeblendete Seiten Seitenfehler aus, die von Linux' normalen Behandlungsprozeduren gehandhabt werden.
Auf einmal eingeblendete Seiten kann bei weiteren Copy-In/Out-Operationen dann nahezu ohne weitere Kosten zugegriffen werden, bei der Lösung mit mehreren Tasks sogar noch nach mehreren Prozeßumschaltungen.
Variante 2 (Abb. [hier]) erfordert einen mittelgroßen Aufwand beim Parsen des Seitentabellen-Baums; die Ergebnisse dieser Operation können jedoch für spätere Zugriffe zwischengespeichert werden. Beim Kopieren kommen kleinere Kosten hinzu, da von Hand auf Seitengrenzen und nicht vorhandene Seiten geprüft werden muß.
Diese Lösung läßt sich so implementieren, daß keine Seitenfehler im Kern-Modus mehr auftreten, so daß das im Abschnitt [hier] erläuterte Problem im Zusammenhang mit dem wechselseitigen Ausschluß durch cli() nicht auftritt.
Variante 3 erfordert einen recht hohen Aufwand zur Verwaltung der Speicherregionen und zum Aufsuchen einer Region; die Ergebnisse dieser Operation können jedoch ebenfalls für spätere Zugriffe zwischengespeichert werden. Dafür sind bei der eigentlichen Kopieroperation keine weiteren Tests nötig.
Wegen ihrer Vorteile wählen wir die erste Variante. Im folgenden diskutieren wir die relativen Vor- und Nachteile der Lösungen mit einer L4-Task für alle Linux-Prozesse bzw. für jeweils einen Prozess.
Die Lösung mit nur einer Kern-Task erfordert ein User-Level-Thread-Paket (vgl. Abschnitt zur Kontextsicherung). Die Umschaltung zwischen den Kern-Aktivitäten erfolgt schneller, aber dafür muß der eingeblendete Nutzeradreßraum ab und zu ausgetauscht werden, so daß schon einmal eingeblendete Seiten unter Umständen nochmals eingeblendet werden müssen.
Die Lösung mit N Kern-Tasks (für jeden Linux-Prozeß eine) hat diesen Nachteil nicht: Einmal etablierte Mappings bleiben über Kontextwechsel hinweg erhalten. Dafür dauern die Kontextwechsel etwas länger, und der Ressourcenverbrauch pro Linux-Prozeß ist höher: Benötigt werden jeweils eine Kern-Task mit zwei Threads (ein Pager-Thread und ein Service-Thread), und die Mapping-Datenbank des L4-Kerns wird stärker in Anspruch genommen. Ferner fällt ein einmaliger zusätzlicher Zeitaufwand beim Erzeugen einer neuen Task zum Einblenden des Codes und der Daten des Linux-Kerns an.
Der Zeitaufwand für oftmaliges Löschen des eingeblendeten Adreßraums und erneutes Einblenden von Seiten (> 20 s) ist wesentlich höher als der für eine Taskumschaltung (3,5 s [22](1)). Daher entschieden wir und für die Lösung mit N Tasks (siehe Bild [hier]).
(Kern-Aktivitäten können keine Signale erhalten.)
In Linux/i386 sind Interrupts lediglich ein spezieller Weg, den Kern synchron zu betreten. Interrupt-Behandlungsroutinen haben die Möglichkeit, auf den unterbrochenen Nutzer- oder Kern-Kontext zuzugreifen und ihn via schedule() umzuschalten (diese Methode zur Kontextumschaltung wird in Linux/i386 von Timer-Interrupt zur Präemption benutzt).
Diese Möglichkeit besteht unter L4 nicht mehr, da Interrupts in separaten Threads ablaufen (vgl. Abschnitt [hier]) und keinen einfachen Zugriff auf den unterbrochenen Kontext haben; die erforderliche Synchronität wird nicht durch Kerneintritt/ -rückkehr hergestellt, sondern durch Höherpriorisierung der Interrupt-Threads.
Daher müssen Kontextzugriffe aus dem Linux-Interrupt-Code entfernt
werden. (Glücklicherweise werden solche Zugriffe nur für statistische
und Debugging-Zwecke verwendet und nicht zur Erbringung kritischer
Kern-Funktionalität.)
3.5.3 Kerneintritt aus Nutzer-Aktivitäten
Nutzer-Aktivitäten sollen den Linux-Kern bei Systemrufen und auftretenden Fehler- und Ausnahme-Bedingungen betreten. Systemrufe sind in Linux/i386 durch ,,int 80'' implementiert, sind also nur eine spezielle Ausnahme.
Um einen synchronen Kerneintritt gemäß der Linux-Semantik zu modellieren, müssen die Nutzer-Aktivitäten auf die Rückkehr der Kern-Aktivität warten. Dies läßt sich mit dem IPC-Mechanismus des L4-Kerns realisieren.
L4 behandelt Seitenfehler anders als alle anderen Ausnahmen: Seitenfehler werden via IPC einem Pager-Thread zur Bearbeitung überstellt, während andere Ausnahmen thread-lokal behandelt werden müssen [15]. Im folgenden gehen wir auf diese beiden Klassen des Kerneintritts näher ein.
Die Behandlungsroutine muß den Prozessorzustand sichern, so daß der Kern ihn lesen und manipulieren kann, dann den Kern via IPC aktivieren und nach dessen Rückkehr den Prozessorzustand (der eventuell vom Kern modifiziert wurde, beispielsweise um ein Signal zuzustellen) wiederherstellen und zum unterbrochenen Nutzerkontext zurückkehren. Da die Behandlungsroutine im Nutzer-Thread ablaufen muß, wird für die Nutzer-Task eine Emulationsbibliothek benötigt, die der Kern beim Start des Prozesses in den Nutzerprozeß einblendet und die die notwendigen Initialisierungen vornimmt, um auftretende Ausnahmen abzufangen.
Diese Nachricht kann auf zwei Arten behandelt werden:
Variante 1 hat den Vorteil, daß der unterbrochene Thread die Ausnahme wie im oben beschriebenen allgemeinen Fall behandeln kann. Insbesondere hat die Ausnahmebehandlung Zugriff auf den Registersatz des Linux-Prozesses, so daß Signale zugestellt werden können.
Die zweite Variante erlaubt keinen Zugriff auf den Prozessorzustand des unterbrochenen Threads, da der Thread bis zum Empfang der Antwortnachricht im vom L4-Kern aufgesetzten IPC schläft und danach unmittelbar an dem unterbrochenen Maschinenbefehl wiederaufsetzt. Dafür ist diese Variante wesentlich effizienter, da sie praktisch kosten-frei ist.
Da Linux Demand Paging aggressiv einsetzt, favorisieren wir die zweite Variante aufgrund der besseren Effizienz. Für die Signalzustellung nach Seitenfehlern benötigen wir daher eine spezielle Lösung, auf die wir im Abschnitt [hier] eingehen werden.
Systemrufe und Seitenfehler sind auch im Linux-Kernmodus erlaubt:
Variante 1 bietet unter L4 keine Vorteile, da der Ausnahmebehandlungs-Code nicht für Nutzer- und Kern-Ebene gemeinsam benutzt werden kann, denn der auf Nutzer-Ebene nötige IPC zum Kern fällt weg.
Die zweite Variante ist schneller, da der Ausnahme-Mechanismus des L4-Kerns nicht benutzt wird. Problematisch ist diese Methode lediglich bei Systemrufen, die ein spezielles Stack-Layout erwarten, wie beispielsweise clone(). Dieses Problem läßt sich aber durch spezielle Wrapper in der Include-Datei <asm/unistd.h> lösen.
Aufgrund der höheren Effizienz fiel die Wahl auf Variante 2.
Der Kern-Pager muß also in der Kern-Task selbst ablaufen. Um Seiten in den eigenen Adreßraum einblenden zu können, wird jedoch die Hilfe einer weiteren externen Task benötigt: Zu diesem Zweck führen wir einen Root-Pager ein, dessen Aufgabe es ist, auf Anforderung Seiten in den virtellen Adreßraum der Kern-Task einzublenden (siehe Abb. [hier]).
In diesem Abschnitt besprechen wir die Zustellung von Signalen zu einem Nutzer-Prozeß. Dies geschieht im allgemeinen kurz vor der Rückkehr aus dem Kernmodus zum Nutzer-Modus.
Die Problematik der Signalzustellung in einem System, das eine Task-Autonomie garantiert, wurde bereits in [6] ausführlich behandelt. Daher soll der folgende kurze Abriß für unsere Zwecke genügen.
Voraussetzung für die Zustellung von Signalen ist im allgemeinen, daß CPU-Zustand (Register) und Stack des Prozesses manipulierbar sein müssen, damit gegebenenfalls Signal-Behandlungsroutinen aktiviert werden können, die der Prozeß installiert hat. Unter L4 ist diese Bedingung jedoch unter Umständen nicht erfüllt:
Daher ist es notwendig, eine Möglichkeit zu schaffen, die Nutzer-Task durch eine extern generierte Ausnahme zu zwingen, den Kern zu betreten. Dies ist jedoch aufgrund der vom L4-Kern garantierten Task-Autonomie nicht ohne weiteres möglich [15]; vielmehr wird dazu die Kooperation eines Threads innerhalb der Nutzertask benötigt.
Dies kann nicht der eigentliche Nutzer-Thread sein; es ist unmöglich, diesen zu zwingen, von Zeit zu Zeit beim Linux-Kern nachzufragen, ob inzwischen neue Signale anliegen. Vielmehr benötigen wir einen dedizierten Signal-Thread im Nutzeradreßraum, dessen Aufgabe es ist, auf Meldungen vom Linux-Server über neue Signale zu warten und dann dem Nutzer-Thread eine Ausnahme zuzustellen (L4-Systemruf l4_thread_ex_regs()), so daß dieser den Kern auf die gewünschte Weise betritt.
Ein Problem dieses Ansatzes ist, daß es unmöglich ist, die Nutzer-Task zur Kooperation zu zwingen: ein boshaftes Programm könnte den Signal-Thread beenden oder sonstwie manipulieren. Es ist jedoch die Semantik der Unix-Signale SIGKILL und und SIGSTOP, auch bei unkooperativen Prozessen zu funktionieren. Daher müssen für diese Signale spezielle Behandlungen eingeführt werden:
In diesem Kapitel stellten wir ausgewählte Lösungen zu Problemen vor, die bei der Portierung des Kerns des Betriebssystems Linux auf den L4-Mikrokern auftraten. Wir beschäftigten uns mit den Subsystemen zur Interruptbehandlung, Zeitverwaltung, Ressourcenverwaltung (Speicher und Prozessor) und Signalzustellung.
Das Ergebnis ist ein aus mehreren Task bestehendes Server-System, das in separaten L4-Tasks laufenden Linux-Prozessen die Services eines Linux-Kerns bereitstellt. Dieses Server-System besteht aus folgenden Teilen (siehe Abbildung [hier]):
Diese Kern-Tasks blenden in einen Teil ihres Adreßraums den Nutzeradreßraums ein, der für Copy-In/Out-Operationen verwendet wird.